
Deep Dive
- DeepSeek 在短短七天内吸引了一亿用户,并使得英伟达股票下跌
- Meta、Apple 和 Google 的工程师对 DeepSeek 的出现和影响进行了深入探讨
- 苹果公司对 DeepSeek 表现出很高的热情,Meta 感受到了压力,Google 则相对冷静
Shownotes Transcript
大模型时代呢用户量可能不是或者说这种数据飞轮可能并不存在因为你的用户的质量不如模型的质量我个人认为这完全就是川普跟 TikTok 公司的一个政治 negotiation 一个政治的 deal
虽然看起来还用了 50 美金但是驱使这件事情就是做这些事情背后的这群人他们的价值这帮人的价值可能已经是人类的最巅峰的智慧了是这个意思吗我的预测是 25 年一定会有一个 major 的关于 AI-safety 的 incident
大家好欢迎收听新一期的实业之评我是小海将中国的农历新年因为 DeepSeek 的突然爆火带来了一系列的连锁反应与科技创投圈的人频繁地讨论甚至连我的父辈都在使用 DeepSeek 问他们理财的知识
DeepSeek 也迅速登上了 150 个国家的 App Store 的下载第一名网络传闻 DeepSeek RE 达到 1 亿用户集用了 7 天随后又带来英伟达的股票下跌 Sam Altman 说 DeepSeek 是一款很 impressive 的应用这个词就很微妙最近 Sam Altman 又开始全球的巡回宣传去了很多的国家甚至 OpenAI 在 App Store 上也投流了只要搜索 DeepSeek 就会跳出 OpenAI
在特朗普上任的第二天孙正义和奥特曼就带着 5000 亿美金去了白宫开发布会宣布他们的 Stargate 星际之门的计划带着这一系列的好奇与探索今天我请来了我的 MetaAppleGoogle 的工程师朋友们来聊聊 DeepSeek 的崛起对于硅谷科技圈的影响我们会从技术创新市场竞争行业影响政策监管等几个方面来聊首先请各位跟大家打一个招呼吧
大家好,我叫一志,我现在在 Meta 做软件工程师,我目前负责的领域是 AI 的安全,简单来说的话就是要确保 AI 生成内容是无害的,是符合我们的政策的,同时也用 AI 的技术去解决一些已经有的安全与合规问题,比如说诈骗内容等等。
大家好 我是谷歌的程序员我所做的工作是优化 AI 芯片在不同的团队之间的配置优化到不同的团队的体验我叫王霜我在苹果负责前话学习的实验和 Generate AI 的部署同时业余时间也做一些异地市场的投资
好的 那首先欢迎大家我想问大家第一个问题是首先大家是在什么情况下接触到 DeepSeek 的当时你们的个人的感受是怎么样的我最早听到 DeepSeek 应该是去年 12 月份的时候当时应该 Own Zero 还没有出来应该是 V3
当时就有看到一些新闻说这个模型效果挺好,但当时应该还没有引起一个这么大的效应。对我来说,其实刚才说的话,是这个新闻最开始变得非常火爆的时候,是 Skill AI 的那个 CEO,Alexandra Wang,她在某个节目上说了,应该是她说那个 DeepSeek V3,oh sorry,应该是 R1Z6 倒是已经出来了,她说这个模型效果非常的好。
是给美国的科技公司一个警告或者说一个启示你说对说的一个给了美国公司一个 bet lesson 因为 bet lesson 是一个挺
听我们一个特征吧就是一个教训可以中文这个视频当时在推特上应该广为流传大家都知道原来中国有一家公司做出这么好的模型然后我开始去了解一下这个模型到底是一般信息以及开始去大概运用一下这个就是我整体了解到的一个过程对我的反应来说的话
或者说我在公司感觉说的话,我感觉最开始的时候是领导层马上感觉自己有压力了,可能是 Mark 层,然后现在的话这个压力慢慢传达到员工这边了,然后需要,因为这也需要一些时间,然后 Manta 也在,我们公司可能也在读,因为在这个事儿,总的来说就是上面铺是更紧,需要大家有更快的能教出一些更好的效果的模型,或者一些别的加快加速一些别的研究工作。
陈燕你的感受呢就是你是在什么情况下听到这个消息或者说接触到它的我就是看新闻的时候看到的我看到的时候我其实没有很惊讶因为我之前就是也做过一些就是模型方面的研究我当时的就是一种直觉就是不应该需要那么多的参数
只是我们暂时还没有找到一个方向说可以让这个模型变得又小然后又好我看到这个新闻的时候我是觉得就是挺开心的我们现在可以这样做了它刚好在你的预料之内只是你没想到这么快就已经实现了对吗对对对那那个王霜你的当时的感触是什么样的其实因为我个人背景的原因我对国内或者国内外的各种大模型公司关注是比较少的
其實 DeepSeek 最早可能是一個 coding 的模型然後當時在榜單上表現也不錯但是我沒有實際用過我本人實際會用一些他們當時是 2.2G 的一個很小 3B local 的一個模型然後這是因為一直能看到直到 V3 出來的時候當時它的 training 成本這個事情已經開始有一些討論了
当时我是有一些质疑因为很多的他当时做的很多事情我了解到在美国公司做的可能也不多比如说用 FP8 来做训练然后当时他们的一些甚至包括他们 M1 的设计都不太一样直到后来 R1 引爆了整个全球的舆论这个事情是非常非常意外的但是他们的模型本身我印象中可能在他们应该是第一个或者第二个能够复现 O1 的这种推理效果的
或者推理能力但是他们叫 R1 Preview 的时候表现还是我只能说很一般他们思考过程非常非常的长然后经常
很长很长之后也没有一个很好的结果但是到 R1 的正式版之后它的能力给我个人感觉和 O1 的普通版那基本上已经是各有所长的感觉不相上下吗对 我觉得是不相上下他们在一些不同的问题上因为我两个都用我会感觉出来就真的是不能说谁更好的确是各有所长
当然可能 O5 更贵的模型或者更强的模型它能够思潮的时间更长我觉得那个是还是有它那时候是有优势的但是如果只是普通的 O1 或者 O3 mini 的那两个其实我感觉和 R1 区别不是很大就是说你现在的感触就是觉得它们之间的差距是非常小的对 给我的感觉差距非常小有的问题
之前的 R1 preview 非常非常一般但是 R1 的进步是非常大的那个区别就类似于你可能想象 GP3.5 到 4 的区别因为当时它号称第一个复现了这个 reasoning 的过程但那个 reasoning 有没有也没啥区别反正最后也是胡说一通但是 R1 的表现完全不一样
你觉得它的表现不一样在有没有什么语言可以表述或者说它就是更好用了它真的可以用了它变得和一个 O1 可以是不相上下的一个模型了因为当时困也做了一个类似的叫 QWQ 我不知道应该怎么翻译但困的推理模型的实际表现当时就和 R1 的 preview 差不多今天可能看来也没有什么太大的进步
那你们就是这个事情出来之后你们公司内部就是大概有一个什么样的具体的反馈呢这个方便说吗我可以说我能说的部分我说首先这个
影响还是挺大的然后最早而且我觉得这个影响是属于从上下传导过来的我觉得 Mark Zuckerberg 应该是第一个对他反应这么大的人包括他自己已经在上了 Joe Rogan 博客你们也大谈特谈 Deep Seek 他觉得 Deep Seek 让他感受到中国公司的压力能说的就是我们对 Mark 对这个事还是非常重视确实产生一些压力需要
push 一些做出一些改变包括有些领导层的改改动可能也是因为这个而来的同时呢嗯我觉得马可会觉得整个公司的文化是需要更加的 aggressive 或者说更加的更卷用中国人来说的话他可能会觉得之前我们公司的有些人可能很多人可能拿着公司但是没有没有那么有效的干活然后他可能觉得中国公司也是不是哎大家都特别努力这是不是他想我觉得他可能会想把这个文化更多的
让在美国他的公司中实现会让整个公司文化更加 intense 一些吧但是呢我不觉得这些事情都一定有效果只能说现在来说的话是让整个公司的研发压力变大了但最终有没有效果呢还是还是不知道的
我觉得好像没有就是特别因为这一件事有什么变化就是从我就是身处的环境来讲吧就是因为像我们组的话我们服务的团队有要求的变化的时候我们才会有相应的变化然后我们现在就是从这个需求上来看我们没有看到什么变化就是仍然是一种供不应求的一种状态路径去走对吗
他们可能模型上是有变化的但是从这种对算力的需求上来讲我没有看到什么变化然后从公司文化上来讲我觉得就是近两年大家都很努力就是在这一点上就是包括职场的压力这些就是在这一点上我没有看到因为就是 DeepSeek 的出现有就是更多的变化我们这边苹果这边还是内部还是蛮热情的因为这是一个
表现非常好的一个开源能型对 Meta 的朋友 no offense 因为比如说 Lama 它的 license 是有限制的我们坦白讲我们内部是不用 Lama 的就即使说内部的项目也是不能用的但是会尝试一些比如说 Mistro 这种有的没的其实也就那样但是 DeepSeek 大家的热情还是非常高首先它的确是完全开放的一个协议用的 MIT 虽然它没有
完整的像大家所说的是个完全开放的一个开源模型但是它这个位置是完全开放的
那么其实没有什么限制然后我们的 LEGO 非常痛快就批准了在很多对内的比如说你用来写代码或者用来生成一些测试数据都是可以的这个的确是非常热情的在试用其他的是不是有团队在复现这个事情我觉得可能是没有因为苹果本身就是一个那种就是
不太着急八分不动的一个公司他是有自己的想法的但是他是比较 open toopen to alternative 这是没有疑问的
就是我自己的工作中也在用然后我看到很多苹果不同的 Argo 当中也在尝试用这个 DeepSeq 不管是 R1 还是 Base Model 它都是在用应用那大家能从技术层面给我分析一下或者说给我讲一讲就是你们觉得就是它这个模型跟过往的模型最大的区别是什么就是从技术层面来讲一讲
从一个终端用户的体会来讲我刚才说过了它和它是一个欧安差不多的但如果从技术本身的角度来看的话其实我的观点和和 Dario 是类似的就是他有一篇政治上不太正确的一篇文章马居先生但是我是很同意他当时文章中的观点是 DeepSeed 它的创新能力主要来自于 V3V3 对于 training 成本的
优化对于 Servant System 的优化都是业界比较或者说最突出的那么一两个之一但是后来的 R1 的出现我不觉得是 R1 本身或者说 R1Z6 是一个特别大的创新点这个我相信所有在美国所有做房地产模特的
一线厂商都在尝试这个事情就是通过用强化学习来做 model 的这个反停连我觉得这个是所有省家都在做只不过 DeepSafe 是第一个公开谈论并且放出这样一个结果的但是我相信比如说像 Meta 像 OpenAI 或者像 Google 它并没有真的发布它有些其他的考量这个也许我们稍后会谈到但是 V3 它的工程的优化是非常非常突出的
甚至我们今天可以看到有很多 R1 的公开的第三方的服务比如说美国这边有很多 Library Gatherer Fireworks 然后甚至一些云场商业都有国内都有但是他们的所有的 serving 的速度是远不如 DeepSync 官方速度的这差距是在两倍到三倍以上
就是因为 DeepSync 本身就是人家自己的模型上对这个是有专门的优化的甚至他们在 serving 上甚至做了类似于 preferring 和 decoding 的这种分离这个我相信很多厂商是不做这个事情的因为它都很复杂然后表现出来的就是人家可以用的确是用更少的卡做到了更高的效率
然后我们看我们实际体会一下就知道你在的该找出发布过程他的配网的是 dpr1 的表现他那个 token 的那个兔的速度和官网他不挂的时候兔的速度那那挺差的别的我觉得这是非常强的呃工程上的优化我其实同意就是我觉得他整体上
最大的一个方向来说其实也是大家都一直在做的并不是没办法没有做就比方说 recently 这一块然后或者之前 V3 的 Moe 架构我觉得 Moe 架构是从 Mistro 出来之后大家应该都在做没有不做的它的创新在于它的非常强的极致的工程能力以及在 GPU 有限的情况下用这样的工程能力去做出这样的优化对于大厂来说的话其实之前很多时候
大厂不缺卡,就是没有那么缺卡至少来说我能所看到的是我们其实很多时候我们知道这地方有效率优化的空间但是我们没有这个时间,没有这个精力,没有这心情去做反正卡目前也还足够所以我们可能就混着过去的也不会去专门去做什么效率优化,GPU 的优化 DeepSync 出来之后其实一定会在这方面有所改变因为
现在比方说对我们来说我们要申请卡那 Litership 一定会问你们这个东西能不能为什么别人可以效率优化到这么高你们为什么不能然后以前的话这个问题可能就不会问会直接把这个卡给踢了但现在可能就会问所以我觉得这可能是一个很大的改变会 push 大家更多是追求
在效率上更加着重吧然后整体技术来说的话其实我觉得应该改变不会特别大因为这些技术现在都是大家一直在做的事然后但是 DeepSeek 它有我觉得它有非常强的工程能力团队应该有很好的 culture 然后才能实现这样的非常极致的工程能力
比较诚实的从用户的一种感受来说我自己现在其实没有怎么用这些产品因为我之前用的体验我感觉它返回的结果不太可靠我就想听你这种话因为我自己觉得说虽然很多人都跟我说如何如何好但是我觉得大部分时候
就是所有的 AI 的模型都给我的反馈让我觉得我并没有那么的满意然后他们就会说是不是因为你不是特别会问问题然后或者说你不太会训练这个模型所以导致你总是对 AI 的输出不是特别满意但是我即使用了 Deep Seek 或许他的回答是所有模型里面就是人的感触最强的但我依然觉得那个人的感触在我看来会是一种
形式的人感我不知道能不能明白我说的形式的人感就它表现出一种那是一个操作程序所以后来我就对于大部分的 AI 对于我来说就是承担一个更高阶的搜索的功能
嗯我觉得首先我觉得第一点就是如果是你觉得他不够好那就一定是他不够好也不是你的 prompt 有问题因为好的模式应该就是可以足够你不知道任何的 training 你可以足够就可以写出足够好的 prompt 然后这样的人那你们太太就是你们太宽容了你知道就是我任何时候说我觉得呃
市面上大量的大模型就是 AI 给我的用的感触不是特别好的时候就所有人都会让我反思是不是你不会转体的东西对就是所以你这个答案是这么长时间来第一次有人跟我讲你知道吗因为对因为好的模型一定是让所有人都可以接受的因为我们不管如何我们包括节目听众可能说很多已经是受过高等教育的人了你要让很多没有接触到那么好的教育的人再用如果有我们都觉得使用起来有困难的话那你要让更多的人怎么去使用 AI 那一定是 AI 的本身的问题
因为前两天突然释然了今天中午的时候我说每次我自己写过一篇文章之后我就把我想写的这个思路放到 AI 里面我就想说让 AI 帮我就是帮我生成一个他认为好的文章然后我会发现我觉得 AI 只能给我一个 40 分的文章就是从我的文学审美来讲因为前两天那个 minimax 的简总
因为是谁晚点还是哪个媒体采访他他就提到一个晚点说他觉得大模型时代呢用户量可能不是或者说这种数据飞轮可能并不存在因为你的用户的质量不如模型的质量
就是說這個人用的越多他並不一定能夠提高對 因為他模型就是為什麼你的周圍的人告訴你說是不是你不會用因為他覺得這模型非常非常好但是從模型的提供者角度來看這部分數據是沒有價值的
大量的人问的问题可能就是我应该怎么找一个好对象或者是今年的运势如何或者 DPP 最有名不是算命吗或者模仿什么推八的语气说个什么话这种数据对于模型的提高是没有任何帮助的就是为什么就是你越来越用户虽然多但是它并不能够真的生成一个很好的真相反馈它只是噪音越来越多
对而且我前两天看了一篇文章我不知道是哪个媒体写的然后他就把这个幻觉率就是不知道用什么一个方法就换算出来然后就会发现就是那个 OpenAI 的幻觉率和这个就是 RE 的幻觉率好像据说不知道是 RE 还是 V3 的幻觉率高达百分之十几但是那个 OpenAI 的 O1 的好像只有百分之零点几
它是有可能的我们从 R1 的 paper 来看的话它的做法是先用 R1-0 然后 bootstrap 了一堆的或不能一堆 bootstrap 出一些能力来然后再加了一些 reasoning 的就是 SFT 的内容来去翻听它的东西但是这个过程我们从这个描述来看它并没有很多
能够减少 hallucination 的这种措施在里面甚至说减少它的 AI 的这种 accessibility risk 这样的一些措施在里面然后其实我们之前很早可能 JP4 的那个年代刚出的时候大家就知道一个模型如果说它是完全提供它的 raw capability 的话它是非常非常强的
但是你在上面加了什么 Sifted Control 尝试 Reduce 它的 Hallucination 然后罗了一层罗一层罗一层就是 Debuff 越加越加之后它表现就变得比较平庸了我觉得 Deep Seek 可能 R1 现在更多还是处于一个比较早期的状态所以说它可能幻觉也比较多但的确 Tradeoff 就是它能力也比较强
当他变得越来越安全然后说话越来越靠谱的时候他可能就不像今天给大家的感觉那么惊艳我喜欢这种可能因为我本身就做 AI 侦控上这块然后其实对我们的不管是 Mata 也好 TestBit 也好其实我们我们其实在把这个 AI 产品 launch 到公众使用之前一定是会在上面再加一层专门为安全而做的模型的因为
因為其實只有這樣才能保證我們是出內容是符合
是符合我们的 policy 的然后我觉得 DVC 可能还因为它本身还是一个小公司可能还没有这么多的 legal 上或者 PR 上的 concern 顾虑所以它可能还没有做这个事另外就是安全这一点是非常要做好模型安全这一点是非常非常烧钱的因为你是要很大量的我们英文叫 rat tumor 去主动去发现模型的危险的地方而这一块是很花钱的所以我觉得可能暂时还没有没有在这一方面做那么多的工作所以我觉得很正常
而且他们说那个 DeepSick 是拿那个百度贴吧做的语料的就训练什么的所以你会发现他经常会在
你问他的一个问题他经常会用一些完全没有修饰的比较粗的表达但是大家会觉得说一个 AI 工具或者 AI 应用能说出如此像人的这种脏话他们是觉得很欣喜的所以像这样的东西会在中国的社交媒体上传播的就会非常厉害
包括我前两天在朋友圈 po 了一个文就是我的一个朋友说那个谁哪个城市是江苏城最好的城市
然后他就回的就是那个 deep seek 说是苏州因为苏州 GDP 是全江苏最好的然后我的朋友就说我是安徽人然后他就说那毫无疑问是南京就是他是有一个我们的共识在里面的你懂吗就是安徽是就是安徽省会是南京吗对对对对他是有一个简单共识里面在里面的然后大家就觉得说这个回答实在是太人惊了所以像这样的答案就会在朋友圈就会被传播的非常厉害这样
那这样的回答是在大公司未必能过身未必能过身我们的所以大家就会很欣喜就是诸如此类的东西包括说比如说问一些就是怎么讲算命的问题然后其实算命是我觉得算命是有一种
文法的逻辑在里面的就是他怎么说都能圆回来所以大家就觉得说他算的太准了怎么那么准这样的东西也会在社交媒体上广泛的传播所以好像这种猎奇类的文本就会增加了普通人对于他的滤镜就是说他好像特别厉害能说到我的心趴上这样
我比較希望這樣的聊天工具能夠給我比較可靠的信息我覺得剛才小野這樣描述的我感覺更多的是一種娛樂的功能我希望我能得到準確真實的信息
现在有一个很好玩的事情就是这是一个用死亡逻辑形容还不太合适它的逻辑是比如说 DPC 刚出来的时候它的联网功能和深度思考功能都是可用的后来联网功能挂掉了
联网功能现在还不太稳定但是深度思考一直还行然后大家就不能用联网联网功能本来的意思是说可以加入一些事实上的一些判断比如说你要搜一些比如说怎么评价最近的一些热点事件什么的这是联网功能本身的设计的初衷但后来呢 R1 呢大家用的越来越多在网上 PO 的越来越多
等大家再把搜索打开的时候这搜出一些都是一些 R1 生成的 hallucinated 的这种信息导致同样的问题它反倒给不出正确的答案了就是这个东西这个搜索的功能你开也不是不开也不是你看着搜出来的东西都是一些假消息你不开的话人工星本身也没有最新的知识这就变得非常的还挺困难我就没说搜索的时候不应该搜的就是百度或者 Google 搜索吗为什么搜是 R1 生成出来的内容
因为就是它的搜索实质性它是有本身的这个 ranking 的 signal 在里面的现在 R1 比如说你不管是从什么平台上搜它这个信息量是非常大的
然后而且很多人用了 AI 这个搜索之后呢你很多平台甚至百度贴吧百度知道这种就是很能够开放大家搜索的内容上面大量大量甚至直呼上大量的 AI 生成的内容这个内容本身是真实性是存疑的然后它又会被
下轮的 AI 的搜索在失路进去最后就生成一些似是似的东西出来然后导致说虽然 R1 的能力非常强但是你怎么摘要假信息它也不会生成一个真消息出来大家会觉得 DeepThink 会成为 OpenAI 的一个比较强劲的对手吗你说我们的看法是吗对你们说个人的看法或者说你们技术层面分析感官层面分析都可以
我觉得从技术层面上已经是了呀不是不是要成为还是已经是了嗯嗯因为因为他的他的模型能力已经出现了非常接近 OpenAI 最新的 0103 的模型的能力然后如果从产品层面来说的话那这是一个嗯不
目前来说还是一个 question mark 的问题因为最终来说的话大家使用 AI 好不好用不仅要看模式能力也要看那个产品本身好不好用比如说你刚刚说的模型服务器响应盲这样的问题看它之后是否有能力解决以及它包括整个它如果真的想做传说市场的话它的 products 和 marketing growth 这些能力有没有能力跟上因为我知道 DeepSync 本身不是一个做这样的公司的公司所以
不是非常认识在产品层面上是否能成为 OpenAI 的竞争对手但是我觉得在那个模型研究能力方面上已经是了我倒是有点不一样的看法我从 DeepSafe 那边做市场战略那边听到的消息是他们对于赶球市场是没有任何想法的就压根也不关心什么海外的用户化市场他们是没有这个他们本身是没有成为 OpenAI 的竞争对手的这种行动计划他们还是以呃
基础模型的研究来推动的那其实如果说从另外一个角度来看怎么样都不成为 OpenAI 的竞争对手呢我觉得首先你要有卡这个事情听起来好像有点讽刺但我们看到的情况就是每次 OpenAI 出了什么问题挂掉的时候没有任何一家公司接得住这个流量 Surfing 一定是跟着就挂了就是 OpenAI 挂了之后大家都去用其他的奥特曼你去到 Cloud 上之后 Cloud 肯定是挂的
那么你现在 DeepSeek 这个情况你是接不住这个流量的那么就是说到底是没有卡吗但是 DeepSeek 本身人家也没有没有做一个产品公司服务大众的这样的一个想法在就是大家可能对他的期待比较高但是人家可能根本就就是不在乎比如说他就那么几张卡你怎么服务这么多用户呢当你讨论说你要成为就是目前大家对于 AI 的这种心智上的认同的那家公司的竞争对手的话
你总不能是一个特别特别比如说 tiny 的一个 traffic 我有你 1%的用户你现在我们讲这个 deepfake 多少 DAU 多少 DAU 但是你这个 DAU 不稳定啊你最终我最终还是用我每天还是在用 traffic 因为我可以无限量的聊
那么你其他的工具接不住这样的我聊聊聊哎不能聊了或者到了上线了这个我觉得很难你还是要有卡没有卡就服务不了但就说回来 DeepSeek 压根就没这个想法你可能别的公司可以用它来做但是 DeepSeek 这个公司本身可能并没有这个想法那那我说一个很有意思的事情就是你知道 DeepSeek 应该今天吧他买了 AI.com 的域名就是你如果你现在也是 AI.com 你会挑战到 DeepSeek
没有吧,那是 AI.com 整的活吧,AI.com 是东跳一下西跳一下吧它是被 DeepSync 买下来了吗?我不知道它最近跳了 DeepSync,它就是一个第三方域名,它就是哪流量高,它往哪跳
他是 DPC 这个公司本身买下来的吗这个不清楚的不知道这我不知道但是说现在这个事情这个这个现象如果是的话那假如说他确实是被 DPC 买下来那我不觉得他在做传说化做这个产品上没有野心因为我觉得想法也是会变的就是他原来肯定是没有也没有这个想法但是他现在看到这么多的流量那这就是很大的机会我觉得不一定会坚持原来的想法
当初做出来的时候他当初开始做的时候肯定是没有这种想法的因为我觉得他才开始做的时候那套范式肯定是 open AI 的那种范式就是要有很多卡然后才能把这件事情持续下去然后没想到就是他这个小米家步枪或者说是一个乞丐的模式他也把这事给弄出来了但他我不知道他有可能想法跟之前不一样就可能我觉得现在的这种情况也不是他之前才开始做这件事情所遇到的事情
嗯没错嗯然后现在就是很多公司接入了这个就是 deep seek 嘛就是包括英伟达在内的然后大家觉得说这这说明了一些什么问题或者说会产生什么样的影响吗嗯这个我觉得很正常吧他这么好用大家为什么不接然后还是开源的嗯影响的话为什么当初的时候那个因为他的股票就是突然间就是下跌那么多嗯
這個我覺得可能當時大家的背後的邏輯推理是覺得 DVC 可以用這麼少的卡訓練出這麼好的模型但之前原來的所謂的就是把卡作為 AI 本身最核心的這個說法可能就已經不那麼的確鑿了或者不那麼的正確了那這個時候
因為大家的股票跌一波我覺得也是正常的因為大家可能會覺得我不太需要直接卡了那從另一個方面來說的話之前有提到就是之前有說蒸汽機悖論當時蒸汽機的效率提高之後對煤礦的需求反而更大了因為
因为真机器变得更好用之后大概会更多人用真机器所以整个事反而最后消耗的煤矿反而变多那我觉得 AI 世界就可能是一样的就比如说现在 AI 的本身的升电推理变便宜了那说不定会有更多的应用出来那如果是这样的话那卡会用的更多
然后从下来看的话对英伟达可能反而是一个利好但我们现在也说不准然后但我觉得这一波跌更多还是有很多的市场的非理性情绪我不觉得我们在现在这个时间点就可以就认为英伟达的价值降低了我买方的朋友讲你可能更多的还是一种呃 d risk 就是他他总是要找一个时间去来做一些 self 然后就刚好是赶上这个事情了
那麼我覺得他會找各種各樣的理由嘛如果大家真的在做二極市場的時候看到他只不過這個事情可能吵得比較大他一天跌掉了這個 600 個比例 將近 600 個比例但之前跌的時候也都有奇奇怪怪的理由這個我不覺得真的是因為這個原因導致他跌而只是想讓他跌的人利用這個消息
那那个比如说现在所有的就大家觉得他很好用所有的这些呃厂家都介入了他的这个 deep seek 那最后续会有什么样的影响吗就对这个比如说所谓的模型的促进或之类的我不知道他会有什么正面或负面的影响吗你看员我自言嘛就是就是这个道理吗啊
就以后之前大家可能会觉得大模型会是比如头部机军的几家然后 OpenAI Google 然后 Anthopic 然后开源有 Meta 但现在就是有了 Deep-Seed 之后可能我相信成成于动的公司会越来越多所以这头部厂商可能就不是三五家而变成三五十家这种都是有可能的尤其它证明了说我的付钱成本也没有那么高
那么我觉得资源大模型的公司会越来越多了大家说 DeepSeek 是一个安卓版的 OpenAI 实现成本很低那么跟 OpenAI 对比分析一下未来的话它还是能够按照这个路径就低成本的实现下去吗它能持续的以低成本的逻辑去运营它的公司吗我相对看法还是乐观就觉得也许可以做得到
因为很难讲但是其实我还是说他那个成本可能并不想像大家想的那么低呃因为前两天呃 Google 不流传出一份啊 Market Intelligence 他们做出来的一份分析吗他们预计说呃
DeepSeek V3 的 training 成本就是被传的神乎其神的 training 成本是和 JPT 4O 的成本是差不多不能说差不多 4O 还要高但是高不到一个数量级大概是一个大不了十倍 4O 是好久之前的模型了那么其实他们衡量 training 成本是用这个 plot 来算的
你多大的模型需要多少 flops 然后这个就算出来可能比如说 V3 大概是三个 eflops 那么可能 flow 比这高高不了太多所以说那么基本上大家可以认为 DBC 可以跟得住一线厂商的成本优化的措施因为工程优化其实没有秘密可言
他不用说我看到你的 paper 我才能做那么基本上大家都能做是证明 DPP 可以跟得住那么我就挺想认为他们能够跟得住这个成本并不会出现以后跟不住成本会反倒提高我觉得不太会但成本并没有大家想象中那么低这是我的一些看法
我记得马斯克好像在 Twitter 上说对于他们是不是用这么低的成本来实现提出了质疑我不知道你们有没有看到那个信息看到了但因为马斯克他们是大力出奇迹的最大的推动者他们就觉得卡就要多买多好卡多才是能力
不能把这些卡连起来现在 DeepSick 说我不用那么多卡我就 2048 张也能存取一个 WasteRay 了那么这些卡多的公司自然是不太乐意看的因为没有人可以真的去审核 WasteRay 从开始顺应各种实验然后数据这个你合适不了但大家只能说从 WasteRay 的规模上来看 2048 张卡是完全够用的
这个是技术上是没有任何疑问的但是至于这个称量多少轮这个你不好说只不过这一定是卡多的公司是不太愿意看的因为马斯克每次融资都是号称我这个卡的规模又到多少了我现在是 H200 的卡次然后下一步又是什么 GP200 的这个大家的叙事方式不一样他一定会质疑的
我看到的一个分析是说 DeepSeek 它还是花了好像是五个亿来建它的数据中心然后也花了很多钱招人什么的它的投入还是很大的
只是说最新的模型它这个 pre-training 这部本身不是那么的 costly 它要能走到这一步它肯定还是花了很多钱它最后的比较小的模型我觉得它可能更重要的价值是说它之后做 serving 的时候它每 serve 一个用户它不需要那么多的算力
你的逻辑就是他其实是花了很多钱的只是说他最后用的卡没有那么多他整个这件事情就花了很多钱其实他最后在训练的时候这个模型他用的卡数没有那么多对吧对对然后他真的用这个模型来 serve 大家的时候理论上他可以更 scalable 因为每个用户需要的算力更少
明白就他如果作为一个基建型的事情去理解他他未来就是在基建上就是搭载更多的就是用户他所付出的成本理论上是应该比其他家要少的是这个意思吧
但是它现在开源了所以就是其他家也可以就是做到跟它就是差不多的成本那就是在 DeepSeek 没有火之前然后很多公司都觉得说 AGI 比的是能源然后很多就是大佬们就是美国的大佬们也投了这个比如说核能源相关的东西那有没有可能说大家的潜意识里面觉得说 DeepSeek 的低成本是一个伪命题啊
大家觉得最后它还是一个军备竞赛然后需要投入很多的这种能源包括很多的金钱很多的成本在里面所以才会有所谓的什么 stargate 这个东西就是孙正义带了五千亿去见特朗普这件事情我觉得目前来看我觉得美国起码或者 VC 或者政府这个方向对这个事情没有 overreact 你看 Anthropic 的最新这一轮 close 了
然后 OFIA 也在荣幸他有没有那么全部好说但请把人家也要宣称了然后最近发的财报比如说 Amazon 他们一年就要投入 100 个 billion 的 kb 大家还是在朝着军备的方向在努力的然后可能半年前我听 Anthropic 的做算力的负责人说可能美国用来 train foundation model 用的电
已经达到全美电力消耗的 low single digit 了就是 4% 5%这样一个量所以说会有很多人投能源这样的一个方向我觉得但是其实从最近的各种不太真实的一些数据比如说什么 5000 亿然后 1000 亿一家公司 1000 亿这种数据出来大家还是朝着军备的方向在走的并没有说因为 DeepSeek 我大家就改了路线了目前看来
是没有的这些都是非常新的数据我就看不到转向的可能性而且就是我今天就是去复现历史嘛然后就我觉得这个历史就很有意思嘛就当年就是好像先是德国人发现了诱的核反应然后他们就说要去制造这个原子弹还是什么的然后后面因为美国人怕他们先做出来所以他们就先做了那个曼哈顿计划嘛
然后后面好像是又是要发射卫星还是什么的然后是苏联人先发出来一个卫星然后就促成了美国去建 NASA 然后我今天在想说这个因为这个 OpenAI 肯定是先做出来的然后之前这个 OpenAI 要跟微软去做一个好像叫水星吧之前的名字好像叫水星计划
然后后面嗯就是特朗普上上任之后好像立马就有这个所谓的心机之门的东西然后之前的段子是说孙正义呃说呃总统先生我要带 1000 亿去发展这个美国的 ai 什么的然后特朗普说 1000 亿哪够什么至少 2000 亿
然后在那个发布会上我记得然后孙正义就说说总统先生我这次带了 5000 亿过来需要发展这个东西因为美国是个什么厉害的国家所以我就在想说就是好像两套叙事一直在按照自己的逻辑去走就是
愿意按照美国叙事的那套人就在拼命的去叠甲叠那个军备竞赛然后其实中国主要的那些就是最早的所谓的 AI 六小龙或者六小虎之类的东西也是按照那套美国叙事的走的只是说 Deep Seek 的突然出现好像像一个鲶鱼吧我不知道应该怎么形容就突然间大家发现了还有另外一套叙事可能存在的逻辑
对其实我觉得 Deep Seek 的成功肯定是会给美国的政界包括大企业的高层产生这样思考的只是现在在行动上肯定还有之前的惯性肯定不会立刻的转向 Stargate 我相信也不是 Deep Seek 有的时候才出现一定之前就已经在有了然后比方说我想提到就是
最近我看到那个之前 FTC 的前主席林海汉他就说了 FTC 是美国的反垄断机构他是对他就说了 Deep SeekProof 了证明了他之前所说的话是对的他觉得我们在 AI 这个科技创新领域应该多鼓励长期的发展而尽量不要让大企业把所有的卡都买光这是他一直以来的叙事所以我觉得至少在美国
雖然林大漢現在已經離職了但我覺得在政治一定是有這樣的思考只是我不覺得現在這個情況下
会立刻转向我觉得大概率包括特朗普他本身也是一个喜欢类似军队精彩这样这样叙事风格的一个一个 administration 虽然说这个 DeepSync 他把这个成本降下来了总的趋势还是会加大对这个 AI 芯片这些基础设施能源的投入因为
因为现在的 AI 其实还是不够智能的从我的角度来看我觉得人的需求肯定还是会希望它能够变得更智能那么如果说这么小的模型然后可以做到今天的这种程度那我觉得大家肯定会希望说我可不可以用更大的模型然后做得更智能然后让 AI 更加的有用
然后因为他把成本降下来了就是更多的人可以去用 AI 用 AI 的人会更多这个需求会变大对这种就是硬件的需求也会相应的变大
我觉得现在 AI 应该是远远没有发挥它所有的潜力的这是我自己在工作当中我觉得我做的很多事情完全可以用 machine learning 来做然后如果说就是我们真的有一天可以用 machine learning 来做很多事情的时候其实这个需求量还是很大的考虑到就是 AI 在军事上的应用的话我不觉得就是任何国家会减少对 AI 的投入
嗯 明白那就是美国现在有去就是怎么讲主流社会有去封锁 DeepSeek 的这样的声音吗反正我知道是很多欧洲国家然后印度吧好像都包括中国的台湾地区好像都在说要封锁 DeepSeek 或者说不提倡使用它那现在美国大概是一个什么样的声音就方便有人来分享一下吗
我看到的是有一些 嗯 紅州的州的立法機構阻止 禁止了州政府僱員在他們的工作手機中使用 Deep-seek 然後理由大概就是
因为觉得你们的数据如果你们手里这个数据你的信息可能会被 DeepSick 这家中国公司收集然后可能会分享给政府中国政府我觉得这是 Far-right 极右派一贯的叙事就任何中国 APP 在他们手中都可能会变成这样所以我不觉得这是一个 AI 独有的叙事其实他们就喜欢这么干
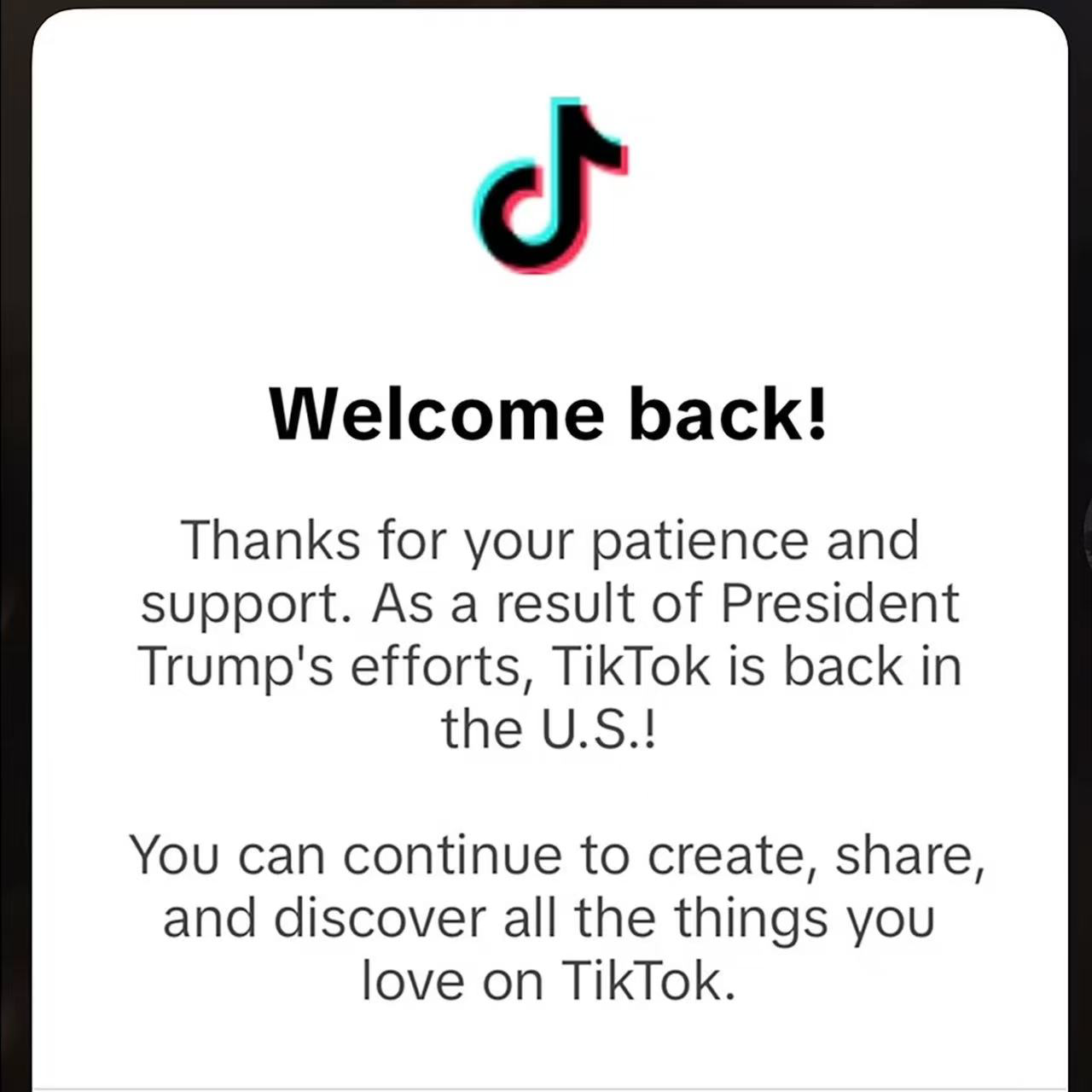
那我顺便插一句就是之前就说封锁 TikTok 然后现在又不封锁了你们觉得这是一个什么操作呀我个人认为这完全就是川普跟 TikTok 公司的一个政治 negotiation 一个政治的 deal 我觉得目前来说就是政府给
川普政府给了他其实五天的额外时间还换取了 TikTok 在 App 上给川普打两次免费广告向所有所有用户推送这也太那啥了吧这是完全一个非常赤裸裸的政治教育觉得好好笑啊
我觉得就是有点荒谬就是怎么说政治的最后就是荒谬如果你有看到那个 TikTok 广告他就是制作就写着 Thank you Trump 就真的是都不知影视的就是暗示什么就是纯粹就是一个一个政治广告这个礼拜吧反正传的比较多的东西就是李飞飞用了 50 美金就做出了类似于 Deep Seeker 这样的东西
然后就是也有很多声音有人很质疑有人觉得说啊啊其实好像 deep seek 也没有那么厉害吗你看别人用 50 美金就能做出来了你们有什么样对这件事情有什么样的看法吗我大概看了一下李飞飞他们团队的工作他大概是使用了非常非常少量的数据集然后在让模型在一个某一某几个 benchmark 的 task 上产生出的推进特点能力但这个推进能力是否是可以
是不是一个可以放话到日常的生活工作使用中的是一个存疑的问题但我觉得这个工作非常 creative 肯定是非常厉害的但它最终能否真的有用我觉得不知道然后我觉得大概应该是不能浮现到所有的放话到所有的日常工作使用中的但我觉得这是一个非常 creative 非常有意思的 work 就它可能只是一个试验性的东西对它是一个很好的试验对 ok 你们我觉得嗯对因为看到呃
他们的工作我觉得很重要一点是你要能够问正确的问题他们是从 Gemini R-Thinking 那边抓下来的数据大概说我记得是条数可能 1000 条多多少条的这样一个高质量的一个推理模型的生成的数据然后来去 finding 他们自己的模型就是你能够问出合适的问题这个事情是很重要的不是所有人都能
对他们只用了多少张卡然后跑了半小时然后合算出一个 50 块钱的这样一个结果但是你找什么样的人来问这样的问题呢那就是不一样的事情而且他就像就是虽然看起来他用了 50 美金但是驱使这件事情就是做这件事情背后的这群人他们的价值这帮人的价值可能已经是人类的最巅峰的智慧了是这个意思吗
对呀对呀就是我今天看到一个说法就是现在 AI 的研究员在 top tier 的 AI 的研究员可能每年他的 compensation 达到一个 million 甚至更多那么一个 million 是什么概念呢你一个 million 上 Gemini 2.0 Flash2 token 能吐 2 万多一个 token2.3T 的 token2.3T token 已经大于大多数
大模型本身用来吹静的 token 数量这里面是有一个非常大的一个这个干费的你需要什么样的人来来帮你做这个事情这些人本身是很贵的
李飞飞他们团队还非常 solid 这个没有什么他们不是为了说整个活啊或者拿点关注度他们也不需要这个明白他们只是为了证明这个技术路线的可行性我觉得这个工作本身是很好的这个没有疑问最后两个 part 一个是大家可以预测一下比如说今年或者是接下来的这个 AI 下来道可能的走势是什么另外就是有四个听众的收集过来的疑问然后我们回答一下就先说一下预测的问题
我觉得其实挺难预测的它这个开源的东西出来之后应该会有很多就是 startup 可以利用起来吧我觉得可能会有一些新的技术突破出来然后甚至就是不排除跟这个 DeepSeek 就是差不多一样影响的突破出来我觉得就是还挺难预测的可能就是过几个月之后就不会再讨论这一家公司了 maybe 是另外一家
其他的 startup 都有可能
我的想法跟你类似就像一个军备竞赛或者是一个打牌的过程就是一个牌桌上的过程然后好像去年年初的时候 2023 年的年末 2024 年年初的时候那个时候是 CHAPGPT 很火的时候然后到 23 月份 34 月份的时候是 KIMI 火了很长一段时间然后后面就是长时间是豆包就是那个字节跳动的豆包砸了很多的钱然后
然后到年底的时候 DeepSeek 就开始变得非常火爆好像就是每个人都能上牌桌玩一阵子或者说每个人都能在社交媒体上火一阵子我的预测是二五年一定会有一个 major 的关于 AI-safety 的 incident 展开解释一下呢我不是针对 DeepSeek 就是说 AI 安全可能在两年前三年前听起来是很可笑的一个事情
但是现在你看 AI 的不管是它输出文本的能力还是它 manipulate 这个信息的能力甚至说它可能会被一些什么样的人利用的这种可能性我觉得尤其在开源模型的巨大突破的今天 25 年会有一个我现在不好说是什么样的东西但它可能是模型本身突出了一些
不安全的内容有可能是被一些不安全的人利用起来但我觉得 20 年会有关于 AI safety 的一个很明显的重量级的话题
说实话我去年一年见证了无数的 AI 事故但是可能他们都不做过大传统一个就是属于震撼型的比方说简单来说我记得前段时间有一个人因为是快到的 AI 还是他的因为使用了 AI 然后后来因为性乱问题自杀了然后还有前段时间特别火的是那个韩国的很多女生因为她们的照片被用来进行 AI 生成 AI 色情图片然后选择了关闭了她们的 Instagram 甚至这个事情一直一度导致了麦塔在韩国的
流量下滑了然后包括我去年做竞选正竞选的时候还真是遇到无数的无数的 AI 安全事故就时不时掺不干的事发现我们 AI 又不行了又要改进了但我确实觉得今年接下来有几个事一个是
一个是像现在发现开源模型可以像 DeepSeek 这么强大不仅它没有因为它是开源的第二个 DeepSeek 本身也没有可能也不是一个大公司没有那么多合规风险它可能会给了更多的让一些不好的用户一些机会第二个我觉得是因为整体 AI 的竞争的趋势会越来越激烈所以各公司会紧张下调 AI 的安全的
因为安全的标准一旦调高你这个模型能力就一定会下降这是不可避免的然后所以因为竞争越来越激烈所以大家一定会下调 AI 的安全的标准然后这其实也会带来越来越大的 AI 风险所以我觉得你说的很有道理让我们可以拭目以待然后回到
回到这个话题就是 DeepSeek 的影响我觉得它出现对我来说对我们来说是一个我觉得会对很多小公司来说会有很大启发原来很多小公司可能会不觉得自己有能力去做防灾层模型包括 OpenAI 它一直在说就你们这些小公司别做防灾层模型了就用我的不然你们肯定没有生存机会但我觉得 DeepSeek 出现证明了这个事不一定是不一定就这样的所以我觉得它对市场来说一定是一个很好的
能起到一个很好的假论作用并且我觉得应该会带来很好的新的竞争机会尤其是在 foundation model 领域最后有几个问题就是那个收集来的这个听友的一个问题就你们的感觉就是 CML 他们会觉得说他一系列的举措是一种他慌了的表现吗因为他现在不是又是什么世界巡演又是买那个热搜
然后又是什么星际之门就是感觉好像有很多骚操作的感觉然后在国内的舆论里面会觉得说他买热搜这个行为就说明他慌了我觉得首先世界巡游和星际之门计划一定是他之前想做的事儿
嗯我觉得和 deep seek 无关啊因为首先信息之门这个计划本身就需要很长的谈定我不觉得是 deep seek 出来之后他们才有时间想然后关于世界使用这个事儿 Sam 已经不是第一次做世界使用了并且我个人他他个人是很享受是这样讲世界使用的活动的所以我不觉得这样是有什么关系然后马月松这个事儿此次确实是我觉得他们的产品团队想到的就是一个
反患於未然吧,因為現在他覺得某些情況好,雖然可能 DeepSeek 目前還沒有在產品上可以真正的和 OpenAI 在用戶流量上競爭但是我覺得他們是一個反患於未然的想法,但是這個事本來很小因為他只是買了 App Store,DeepSeek 那個詞條,我都不覺得不一定是三毛團本人的決策,說不定是他們下面某個產品 VP 或者 Marketing 的 VP 的決策所以我不覺得從這些信息中能推測出三毛團
真的慌了怎么样反而是他提到说他可能会重新思考是否要让 OpenAI 这个事开源或者在某些程度上进行开源我觉得这个反而是他我觉得是一个他想要他的改变吧然后我觉得这个是如果他真的有一这么一些开源的或至少部分开源吧我觉得对 AI 的整个业界来说应该还是有很好处的其他两位有没有补充
我是同意一致的看法就是开源是一个挺大的触动因为这次 DeepSync 能够引爆这个话题我觉得主要原因是因为它开源而且这个聊天服务是比较浅的但是 O1 呢其实真的用过的人也没有太多大概比如说有数据说 O1 是比如说在 Plus 里面大概是有大概是一个一千多万的用户量级
然后 GP Pro 大概是一个不到 20 万用户吧
那麼實際上雖然聽起來很多但是你如果從全球人口來講那麼和 DeepSeek 這個輿論差遠了所以說他會考慮一些開源的方式我覺得這個是挺大的一個變化因為之前他完全沒有這方面的考量但對於說 App Store 關鍵字這個事情我覺得這個是常規操作大家你去 App Store 上看基本上都會有競爭對手買
买精品的关键字这个是没有没有不奇怪这不可能刚刚想到了然后像 stargate 5000 亿美金和最开始三风说的 7 万亿那已经缩水很多了这个当年这个我觉得都还好这个 5000 亿反正是可能比大家想象中少很多一去以后还有更新的都不好说反正这个钱从哪来也不知道
我是这么看的就相互上的各种谣言就是说说那个 DX 一个抄袭 open AI 然后或者说针流 open AI 的数据就是会有这样的言论存在你们是怎么看这个问题的就是说实话他是否针流
完全不影响他的他所带来的创新和影响力啊就他可能真流可能没真流但是这真的不重要只是我不会说输出来原来问题但是他的模型上的创新和影响力这点这是无可置疑的所以我觉得就不重要好但我们我们也不能我们没有办法知道到底有没有真有就是没有办法证实也没有办法证明的事情我这边想法就是他现在很多人对于啊但我不是说呃 dixie 到底真还是没真哈这个嗯老板弄
但是现在很多人讲的 DeepSync 征流的证据可能不是太站得住脚他们征流的证据是说比如说问 DeepSync 你是谁或者谁 vote 你这样然后他吐出来一些类似于我是 OpenAI 的什么什么 model 我觉得这种关于模型本身身份认定的输出不能作为征流的证据
或者说因为从模型叔叔的这个原理来讲他是说当你问我一个 model 的话我只说取一个最大概率给我告诉你我是一个什么 model 但是什么 model 的概率最大呢自然是欧风爱的 model 嘛
这个事情是不能作为争扭的证据的但是另外有些人的观点是说 DPC 游戏 V3 的输出和 XFGT 的格式几乎是一样的这个是你没办法否认的因为 XFGT 都喜欢那种先总结再 Bullet PunchBullet Punch 先黑帖子再有小段落然后最后再来一个截案陈词 V3 的输出模式是一模一样的
然后这个事情其他模型还不太一样比如乱消费机最喜欢用多级标题但是差距 BD 和 DPT 是不用的但是你这个事情能作为证据我觉得也不能就是说它并没有一个直接的一个证据来证明这个事情但是其实因为征流本身它并不是一个法律概念我觉得这个事情需要交给或者说被征流的那一方他们自己去解决
如果欧凡觉得你征流我了那么他们是有权利说砍掉你的 API access 我觉得这个没有问题但是这个不是公众的关注点这是谁被征流谁你自己解决的问题我是这么看的不管中国和国外大家对于 DeepSeek 目前的所有的赞誉是不是有点过誉了然后在实际的体验中其实是 O3M 的效果更好我觉得差不多 OK 它不是一个
子集和超级的关系差不多但是有 overlap 的 OKDeepSeek R1 的很重要的基础是一个基于强可效应的奖励模型这个奖励来自于编程数学等可以有完全正确答案的结果但对于不可量化的文艺商业我们是否也能够做出类似的奖励模型我觉得目前这个问题还是比较开放很多人在讨论但是并没有一个很好的一个
结果出来但是其实证明很多时候它不是技术问题而是一个中断用户怎么感知的问题很多时候大家知道数学或者编程问题是有准确答案的但是对于非这种强可验证的数据集可能大家会用中断用户更追求的是一个我自己叫我不知道有没有人这样说话叫 perceived accuracy 用户觉得对就行那么 D3C 比如上场算命
他算出这个东西大家都知道肯定是不对的但用户觉得他对那他就是对的对于模型来讲这就是一个学对了一个场景他并不需要真的说我验证这个人以后怎怎样了而只是说只要这个用户觉得他对了他就可以这是一个非数据和编程问题之外的一个看法他并不需要真的很强的信号所以从这个角度来讲我觉得是可以做出来的
只不过 M-Line 上不太好于测所以就是 DeepSeek 在某种程度上它给出的答案或者说 AI 在某种程度上给出的答案是一个情绪劳动是吗对啊就是你用户觉得对就行比如说算命我就再说一遍算命这种问题它能算得对吗和算得对算得错都不要紧只要用户觉得对就行那这个就是正确的信号
我觉得这个很好想,我觉得可以,如果真的要做比较重,可以做一个 population fold,就是让比较重算命,让所有算命用户打分,然后用这个作为 signal 去训练他这个算命这方面的能力,因为本身这东西反正,因为只要用户喜欢就行,那我们就往这个方向训练,那我觉得也是,也是,也是能可以的,包括在,也许就可以繁华到整个艺术行业,因为艺术,艺术,
藝術本身不也就是因為原始的話才有藝術嗎那我們也許可以搞一個 user 的投票然後通過這個做一個訓練的 signal 對我覺得按照這個思路的話可能會就遇到一個就是之前可能推薦系統遇到過的一個問題就是說你總是給一個人推薦他喜歡看的東西然後推薦給他
比较有可能会赞同的观点这样他的世界其实也就越来越小我觉得这个可能就是怎么说呢就是就是从社会的角度来讲我们可能就是不太希望这样定义这个就是他会进入新的信息检访对从长远来说不是一个有利的但从某些人的情绪来说可能
他需要这样的安慰剂之类的那下面一个问题是大家觉得 scaling law 是一个伪命题吗然后就是通过 RE 这个路径是否也可以形成新时代下的 scaling law 我觉得就是所有的这种 law 它肯定都是基于一定的 assumption 的就是现在的这个 law 肯定也就是基于比如说现在的这个芯片它的性能
然後可能也基於這些科學家他可能開發的這些效率他基於很多很多的假設但是我覺得這些假設不一定會一直成立比如說可能之後有新的 AI 芯片可能某一天量子計算取得了重大的突破可能所有事情都變了或者常溫超導這些事情
所以我其实就是不太相信就是一定有就是正确的 scaling law 就是所有的 scaling law 都是一个有限的条件下形成的一个问题其他的朋友
如果从比较抽象的角度来讲的话比如说对生物来说它脑子比较大它一定就是越聪明我通常就是越聪明的那也许我们可以假设这个东西在 AI 上也是成立的那如果是这样的话我们的 AI 的实力还正能水平到人脑还有好多路要走那是不是也许只能成立呢所以我觉得我没有办法回答这个问题这只是我的想法我个人会认为至少在一段时间内
Scalenow 还可以走下去但是未必就中间会是一个平滑的直线它可能会有一些 ups and downs 也许我们会找到新的 AI 范式来继续走这个 Scalenow 我觉得 Scalenow 就是一个框嘛什么都能往里装最开始是 training time 的 Scalenow 然后现在变成 test time 的 Scalenow
也许会有别的,这个不好说的最开始发明 SkinLala 这个词的人是非常讲究的他只说了后两个词,他没有说前面的词现在大家讲 Training Time SkinLala 那肯定是没戏了,大家都知道但是现在有 Test Time,也许有别的范式,这个很正常的所以说从这个角度来讲我觉得他是可以继续 Skill 的只不过 Skill 什么东西不好说
X 越来越大 Y 越来越大这个东西是一定可以套得进去的嗯就 scaling out 是一个框差不多能往里抓了
最后一个问题就是来自于一个就是在读博士吧可能然后他就说按照现在 DeepSick 的发展速度或者说很多 AI 的发展速度未来是不是很多的博士生都可以被替代我觉得绝大多数公司都可以被替代不是不是只是博士生的问题但我觉得他既然已经做一个博士生了我就暂时就不太需要担心因为我觉得大概他的工作会在绝大多数公司被替代之后才会被替代
原来这样因为就是之前很多 computer science 同学他觉得说现在的 AI 可能他写出来代码能有一个他觉得 60 分到 80 分左右的水平也有些说从 40 分到 60 分的水平就他的意思就是说他其实已经写得很好了那他就会很担心说是不是就这一类的博士生是比较容易被取代的
就是那些就是没有我不知道那么强能力的那些人他就会被取代掉我这边观察到的是我知道 O1Pro 的主要用户都是科研机构比如说高校或者一些研究所现在 O1Pro 已经变成了这种教授们搞科研的那些必不可少的工具
它已经在相当一部分程度上影响了他们的新的博士生的招聘了同时我们在业界有了 AI 之后实习生都招少了你很多事情 AI 就能做了这个是非常非常现实的问题我觉得这个问题也没有人能回答得了但是现在看到的趋势是它在即使不能百分之百的替代人但是可以相当程度上的替代
那么以后会怎么样我个人是是北管开发的只不过我足够我已经足够资深了所以说可能替代到我那天我已经退休了我明白
陈燕觉得会被替代吗就是我之前有一个同学他本来不是 computer science 的 PhD 但是他想换专业换成 computer science 的 PhD 然后他找一个 computer science 的教授聊这个事情的时候这个教授就是问他为什么一定要换这个专业然后这个教授说的是你的这个 PhD 学位
告诉别人的是两件事第一件事是 You can do research in this particular area 就是你能在这一个领域做研究第二件事情是 You can do research, period 你可以做研究
我觉得可能更重要的是不断学习不断适应环境能够解决问题的能力我觉得可能就是你在问这个会不会被替代的这个问题的时候就是我觉得可能就是可以就是想一想你问的是不是一个正确的问题你是应该思考你会替代吗还是说你是应该思考就是你要怎么样发挥自己的价值
我觉得他这个问题问了让我有启发的一点是什么就是在中国互联网里面有一个已经好几年的一个言论就是文科无用论你看就是包括你们这些留在美国的基本上都是 computer science 或者是
就是那个生物的嘛就是这一类的比较多生物学的博士这一类的比较多那因为就是这种比较好留下来嘛那像在中国招聘也是一样的大家会标注出就是理工科优先然后就是文科就是不太招文科的不管是什么样的岗位现在都有点特别是
创投行业就是现在基本上都说一定是理工科然后最好是博士这样的条件开出来那就会导致说在中国的互联网上有很长一段时间包括现在就依然就是文科无用论所以像我们这种学商科或学金融的人就是常常会有这种无力感比如说我就不会写代码对吧虽然我学过一点但是因为长期不用可能我已经忘掉了然后再上 AI 的出现就让我让我这种人会觉得说我好像像一个现代文盲一样
你懂吗就是这种有时候有一种无力感但我现在在调整自己的心态就是说我应该变得思考说我如何跟 AI 相处或者说我如何用好它变成我的一个工具让它帮我提高我的效率和产能但我会觉得说我周围大部分人都是比我焦虑很多的人
我看到的是如果说我们从现在开始去构想理想中的人和人类社会是怎么样子那如果其实从从现在到那个理想状态其实有很多很多东西还没有做还有需要解决很多很多东西要解决然后我觉得有这么多的需要解决的情况下有 AI 作为一个你的辅助一个工具那我觉得是对我们来说是
是加速了人類往理想社會發展的進程而不是最終而不是說人類會被替代因為時常的時候我們會覺得如果說 AI 能做到這個工作其實有的時候說不定就是有更好的工作有更好的機會等著你的另外就是你剛說的我覺得永遠就是要擁抱新的技術擁抱新的東西或者講這樣的話就不會有什麼
不用太擔心你的未來對 我覺得就是看過去的歷史的話其實也是就是每一次工業革命它確實就是淘汰了一些技術和工作但是它確實也就是創造了更多的這種需要解決的問題和工作機會我覺得主要還是就是與時俱進吧就是其實人生就是不斷的
在学习的一个过程就即使毕业之后也是这样我现在特别关注的一个问题就是工业革命的时候那些纺织女工都干什么了嗯
就是我每次想到这个问题的时候我就会想到就是你知道以前有一个工作叫电话接线员还是什么寻呼机接线员然后自从有了手机之后这些工种就消失了然后那些人大部分因为他们的学历没有那么高和可能就因为这些可能还有一还有一还有一种性别原因就是女性居多可能最后这些人就会走向下岗
然后有一些人会去卖保险然后有一些人可能就是在家或者说去摆一些小摊这样的东西可能过往的冲刷都不会有这次冲刷来的这么的猛烈我不知道是不是可以这么理解还是说历史上所有的冲刷都是这么的在当时的人看来都是这么的迅猛对啊我就不知道我挺焦虑这个问题啊你焦虑你都没有不知道退休了吗
虽然我没有什么鼓舞人心的话可说我是属于要被替代这一波的那么你比如说经纪人下岗之后去买保险现在也可以买保险啊对不对就是我能够我做这个事情做了比如说世界 20 多年那么我在什么领域能够替换掉 AI 呢我是偏悲观的这种在 workforce 的分别上我是不太知道这个问题会怎么样嗯
但是我觉得说到替代这个问题我觉得肯定还是需要经历一些时间和过程的没有那么快的
就是整个世界其实都是在适应它不仅是说需要技术上的更进一步很多也是制度上的包括公司的这种制度上这些都要变化这些其实是肯定会有一些时间的我们也有时间去思考自己要怎么样的
更進一步這樣是有時間給我們做出反應的從另外一角度來說的比方說為什麼一個公司要找人或者比方說為什麼大公司要找這麼多的花這麼多的程式員和產品經理其實不就是因為他們老闆上面的有想法需要這些人來做實現嗎那其實從另外一角度來說的話如果我說 AI 可以取代這些員工那是不是也意味著每個人都可以成為老闆呢因為 AI 自然是要比人總要便宜很多很多的然後你永遠可以找到很多
在未来你可以找很多 AI 员工来帮你实现你的想法
我觉得大家说的都挺好的实际上因为但是人在焦虑的时候其实我觉得抵御最好的抵御焦虑最好方法还是具体就是你干一些具体的事你可能边干边学边思考可能有一些答案就自然而然的显现出来但如果焦虑只有焦虑本身的话就这个问题就是无解的我觉得可能就是 deep seek 就周围有很多大模型公司有 AI 六小龙也还有所有大厂在做大模型然后我觉得特别有意思就是为什么 deep seek 不能走出来这点是特别有意思的然后
我觉得也可能是会对不管中国还是美国的公司会有特别喜发的一个事这个事我没有确切答案但我觉得也许是因为 DeepSeek 它鼓励了非常它应该是一个非常就是偏向 research 它没有很强的功力导向的然后它鼓励大家去自由发挥自由探索也许如果说这样能成为一个启示的话那也是我们很多公司中国不管美国中国也好还是美国也好也需要去反思一下自己的企业文化因为很多时候
很多公司往往就会看中目前的一个什么样的结果那是不是很多时候我们可能就会迷失了或找不到真正该往前走的方向呢就是一个局部最优和长期最优的一个我只看以下的利益我可能从长远来说它不一定是一个对于公司或者对于社会来说它不是一个最优的选项没错好那我们今天就愉快地结束吧
谢谢大家的支持就非常感谢因为确实是时间上面很难协调就如果还有机会的话也希望依然可以跟各位展开这种类似的对话谢谢