
18.企业使用大模型的正确姿势是什么?|专访华为云CTO张宇昕

卫诗婕|商业漫谈Jane's talk
Deep Dive
为什么华为云选择将大模型率先应用于工业领域?
华为云选择将大模型率先应用于工业领域,主要基于华为的基因和中国制造业的领先优势。中国在全球600多个工业行业中,有220多个处于全球领先地位,这些行业的技术经验和工程能力通过数据沉淀,成为人工智能的最佳数据集。华为云通过深入工厂车间,帮助工业企业构建行业大模型,提升生产效率和质量。
大模型在工业领域的具体应用有哪些?
大模型在工业领域的应用包括煤矿、炼钢、水泥制造、医药开发等。例如,在煤矿场景中,大模型通过远程摄像头和声音分析,判断煤层工况,提升生产效率;在炼钢场景中,大模型通过数字化炼钢参数,减少试错成本,提升炼钢质量。山东某矿井在大模型加持下,年产量提升了2000多吨。
为什么云厂商在大模型浪潮中扮演关键角色?
云厂商在大模型浪潮中扮演关键角色,因为大模型需要大量算力、数据和客户应用场景,而云平台能够将这些要素聚集在一起。云厂商不仅提供算力和基础设施,还通过云生态连接上下游伙伴,帮助企业快速应用大模型,推动技术落地。
大模型在气象预报中的应用带来了哪些改变?
大模型在气象预报中的应用显著提升了计算效率。过去,一次气象预报需要几千台高档服务器运算半天,而现在仅用一张卡,10秒钟就能出结果。这种加速计算的能力极大地缩短了气象预报的时间,提升了预报的及时性和准确性。
华为云在大模型领域的独特优势是什么?
华为云在大模型领域的独特优势在于其软硬件协同能力。华为不仅提供算力,还通过自研芯片和硬件设计,结合客户业务场景,优化系统性能。这种软硬件协同的设计使得华为云在算力效率和成本控制上具有显著优势,尤其适合正企客户的需求。
大模型在药物研发中的应用带来了哪些突破?
大模型在药物研发中的应用显著缩短了研发周期。过去,研制一种药物可能需要十年时间,而通过大模型加速计算,药物筛选时间可以缩短到月甚至天。这种效率的提升不仅降低了研发成本,还加快了新药的上市速度。
华为云如何帮助企业构建行业大模型?
华为云通过提供大模型底座和工具链,帮助企业构建行业大模型。华为云深入客户一线,了解客户需求,结合行业知识,训练出适合特定场景的大模型。华为云还提倡行业共建开放数据集,推动行业通用大模型的构建,降低中小企业应用人工智能的门槛。
大模型在炼钢行业中的应用如何提升效率?
在炼钢行业中,大模型通过数字化炼钢参数,如炉温、湿度等,减少了试错成本。过去,炼钢师傅依赖经验,一炉钢60吨的试错成本可能产生几十吨废料。通过大模型优化炼钢参数,炼钢的精度和质量显著提升,减少了浪费,提高了生产效率。
华为云如何看待大模型的泛化能力和专业性之间的矛盾?
华为云认为,大模型的泛化能力和专业性之间的矛盾需要通过技术进步来解决。随着算力的提升和模型架构的优化,未来这种矛盾可能会得到缓解。华为云提倡在特定场景下训练小的大模型,既保持专业性,又通过行业通用大模型提升泛化能力。
华为云在AI Native领域的实践路径是什么?
华为云在AI Native领域的实践路径包括四个方面:首先,选择AI Native的算力,支持大算力、大带宽、低时延;其次,采用AI Native云服务构建客户业务系统;第三,构建行业或企业大模型,将知识经验数字化;第四,基于大模型改造应用系统,实现智能化。
- 大模型浪潮来临,企业面临热情与焦虑;
- 云厂商成为大模型的绝对主角,扮演辅导员和攒局者的角色;
- 华为云选择AI for Industry战略,率先将大模型应用于工业领域。
Shownotes Transcript
「这一次,狼真的来了。」张宇昕对我说。
1999 年加入华为的张宇昕,至今担任华为云 CTO 已有七个年头。从一名基层软件开发工程师做起,先后经历了互联网和移动互联网浪潮(过程中创立了欧拉部),而这一次,他确定,生成式 AI 的技术浪潮,真的与以往不同。
「这一波人工智能让大家看到了泛化与通用——通用就是大家都能用。」
「AI 从一个局部真理,走向了人人都信。」
「人工智能浪潮来临后,没有一个企业说我不用人工智能。」
不过,冰冷的现实是,人们对于技术的畅想无限,而落地时却进展缓慢——这是大模型浪潮迄今经历的,从热情高昂,到冷静务实的 600 多天。
昂贵、使用门槛高、技术仍存在局限,是大模型难以进入现象级应用的真相。
因此,放眼中外,云厂商成为大模型剧目中的绝对主角。他们既是辅导员——帮助一批企业率先用上大模型,过程中也售卖出自己的算力、基础设施和服务;同时也是攒局者——凭借对产业上下游的连接,先实现技术最大面积地应用,并充分观察、统筹、整合,再让产品反向牵引技术进步。
而中国的众多云厂商中,只有华为云,坚定地选择了难度最大的「AI for industry」——要将大模型率先应用于工业领域。
如果将华为视作一扇窗口,便能窥见千行百业在这次新技术浪潮下的众生相——
产业里的热情和焦虑都是空前的。在此情绪之下,一批巨无霸工业龙头,已经率先踏上大模型应用的牌桌,因为只有它们——拥有足够的财力和数据积累,有资格当「第一批吃螃蟹的人」。
一周前,我在海南,创原会技术峰会的现场,目睹了这些令人称奇的先进案例:在生产精煤、炼钢、水泥制造、医药开发与研制、疾病预测等等重要的场景里,贴着行业训出的大模型,能极大地提升这些场景的计算效率——在原本高危、高成本、高精度的作业场景里,大模型能够实现加速计算。举一个通俗例子,过去,做一次气象预报需要几千台高档的服务器,并运算上半天。现在,仅用一张卡,10 秒钟就能出结果。
看起来,第一批吃螃蟹的企业已经尝到了甜头:通过加速计算,行业能够极大地缩短生产周期(原本需要研发十年的药物可能缩短到月、甚至天)、减少生产过程中的冗余(炼错一炉钢可能产生几十吨的废料),从而达到惊人的效益提升——在山东,仅一个矿井,在大模型的加持下,一年的产煤量能够提升 2000 多吨。
那天,我身边的与会人士西装革履,他们大多来自传统行业——但会颠覆你认为它「传统」的刻板印象。因为,在生成式 AI 的浪潮下,居然是中国工业界,现象级地、率先涌现出一批大模型应用的小闭环。
**我在创原会现场,专访了华为云的 CTO 张宇昕先生。**我们谈到了新的人工智能浪潮下,中国产业里的集体性焦虑及其对策,以及华为对于AI Native的思考。
**企业用上、用好大模型的方式是什么?这项技术在哪些行业已经率先落地,具体如何应用?华为所倡导的大模型to B 路线,如何理解?**有关这些关键问题,以及大量华为的内部视角,都蕴藏在这次高密度的访谈之中。
本期文字访谈也已经上线我的公众号《卫诗婕 商业漫谈)》,欢迎大家搜索阅读。
 本期嘉宾:华为云CTO 张宇昕
本期嘉宾:华为云CTO 张宇昕
本期 Shownotes:
03:30 华为云CTO张宇昕:1999年加入华为,历经三波技术浪潮
06:02 华为云的大模型战略,「AI for industry(工业级 AI)」
06:22 中国是 AI 发展的黑土地?
07:04 热情、恐惧、大模型焦虑?——中国企业的众生相
09:48 这波技术浪潮与过往有何不同?
13:52 「这一次,真的是狼来了!
14:24 戳破幻想:人不会的,不要指望大模型会
16:25 无论中美,云厂商都是大模型的做局者,为什么?
17:40 大模型如何改变了云:服务层、模型表达和数据价值
21:05 过去云厂商就像水电煤气,缺它不可,但不会为它支付高溢价
21:36 过去一年,云厂商经历了怎样的竞争?
23:29 华为云的独特优势:算力,国产替代,和软硬协同
26:34 当下的大模型:成本还是太高、效率还是太低
28:17 30+行业,上千个客户,第一批吃螃蟹的客户已经开始赚钱
29:05 把大模型拉下神坛?
29:56 华为不刷榜?通识不解决企业的关键问题,要靠专业专长的know-how
32:55 专业数据训得越多,泛化性就会影响,一味追求通识的指标是个浪费
33:47 就像小学生教多了消化不了,当前大模型的算力效率局限
34:29 大模型客户都是巨无霸?只有大企业有可供大模型训练的数据
36:44 「我们号召行业共建开放数据集:你之优势,能补我之不足」
38:14 把「小」的大模型做好,会是一种趋势吗?
40:26 企业如何选择大模型:专业能力、多模态的组合,以及尺寸
42:31 小参数,但是精度好的大模型,未来企业会不断追求
42:51 华为发现了哪些高价值的 AI 场景?
43:03 用大模型挖煤:一个矿井,年产增加2000多吨
44:46 用大模型炼钢:一炉钢60吨的试错成本,省了
45:50 华为内部的武功秘籍:十六字真言是什么?
48:53 「方向偏了」,「目标低了」
51:16 从云原生到 AI 原生,华为如何理解 AI Native?
51:58 AI Native 的四步实践路径
55:54 现有产品还是先有模型?技术与产品的伴生之道
57:15 「我们如果走美国的道路,不一定能成功」
59:01 中美的大模型差距,需要产学协同,才能进行全栈竞争
 (👆图为中美不同技术层的对位企业对比。)
(👆图为中美不同技术层的对位企业对比。)
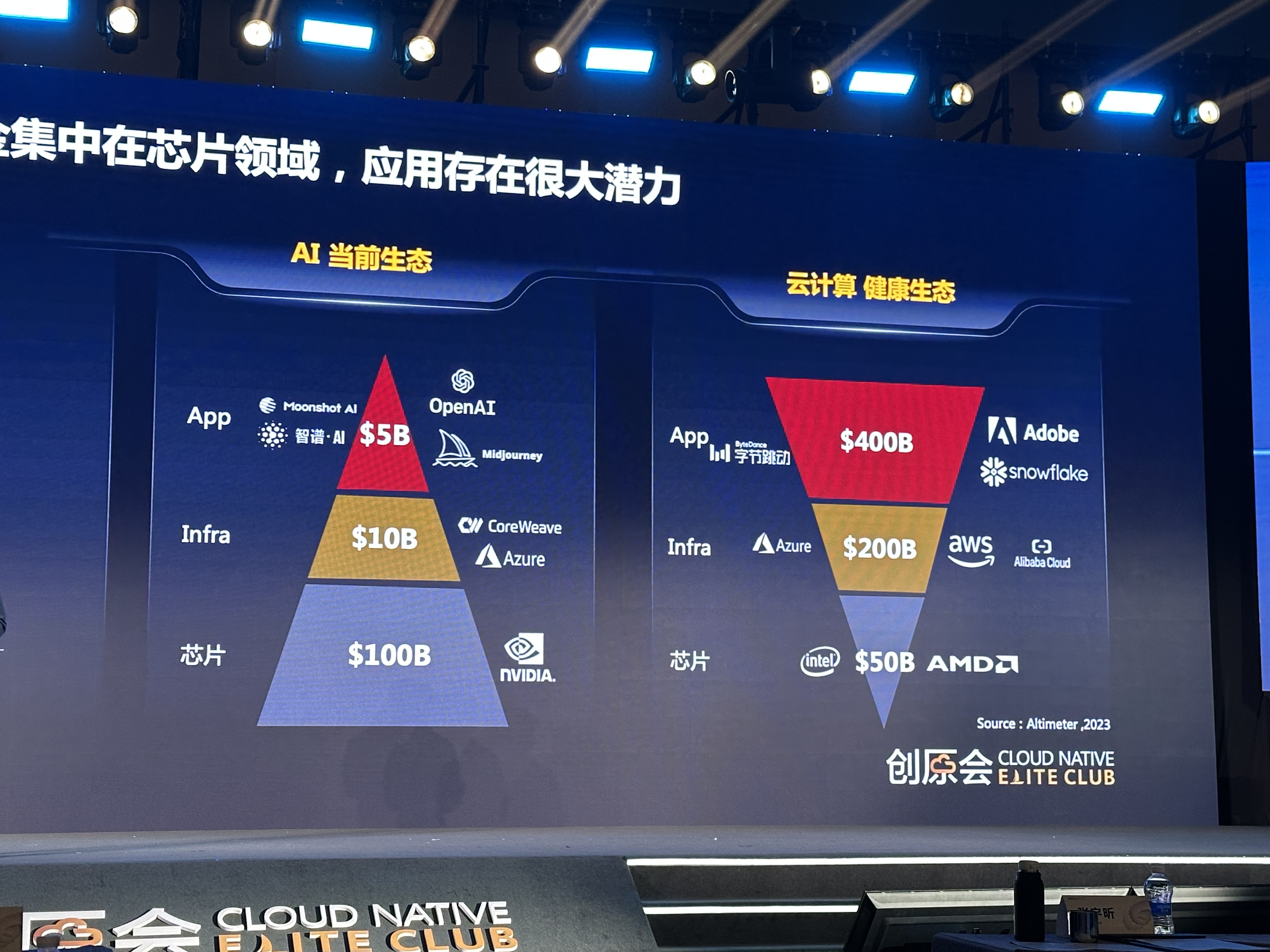 (👆云与AI,生态的三角和倒三角。)
(👆云与AI,生态的三角和倒三角。)
————————
加听友群,请添加微信 shangyemantan
商务合作、联络《商业漫谈》,请添加微信 SJ_Jelyne(添加需备注职务来意)
欢迎搜索并关注我的公众号「卫诗婕 商业漫谈)」。
 有关主理人:卫诗婕,独立商业作者,曾任《极客公园》执行总编,早年任职于《人物》、GQ报道、字节跳动。代表作:《ofo的终场战事》)、《罗永浩:薛定谔的理想主义)》、《朱一旦的枯燥生活)》、《中东社交十年风云:金矿、折戟、浪潮再起)》、《下一站,沙特)》等。作品曾获虎嗅2024年度作者、金字节奖年度新锐作者、网易非虚构文学奖年度作者、全球真实故事奖中文报道十佳。
有关主理人:卫诗婕,独立商业作者,曾任《极客公园》执行总编,早年任职于《人物》、GQ报道、字节跳动。代表作:《ofo的终场战事》)、《罗永浩:薛定谔的理想主义)》、《朱一旦的枯燥生活)》、《中东社交十年风云:金矿、折戟、浪潮再起)》、《下一站,沙特)》等。作品曾获虎嗅2024年度作者、金字节奖年度新锐作者、网易非虚构文学奖年度作者、全球真实故事奖中文报道十佳。
有关「商业漫谈」:这是一档关注科技、商业、人文的深度访谈节目,致力于记录时代的商业史。聚焦商业趋势、伦理、竞争、价值。
「打捞时代碎片,文字对抗时间。」