【原理】
效果
效果评估,从推理的延迟来看,利用这个原理,可以极大地缩减延迟时间;
手机的结构
比如16G-512G , 前面的16G指的是DRAM, 512G指的是Flash Memory。GPU和CPU是处理问题的大脑,从Flash -> DRAM的带宽是1GB/s, DRAM到运作是100GB/s, 我们在使用大模型的时候需要的是低延迟,所以就需要把模型参数放到DRAM里,但是,模型参数不够放置DRAM,比如7B的参数模型需要14G的DRAM。所以需要把参数存在Flash Memory 然后想办法在DRAM里面存储有用的参数。
大模型参数的稀疏性
首先大模型上大部分的参数都是0,所以稀疏性很大。
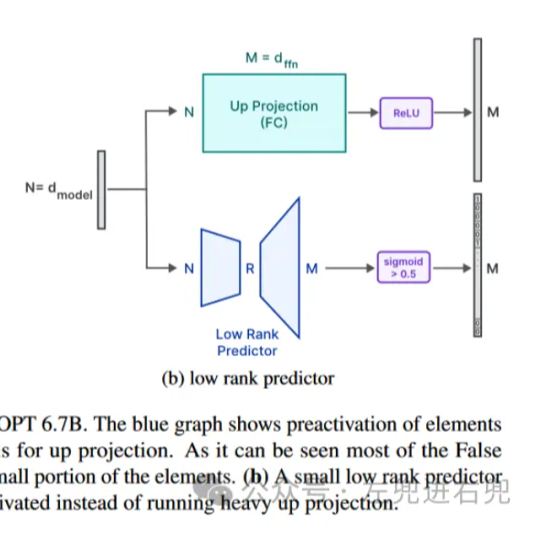
使用的办法
(1) Windowing 使用滑动窗口的方式,每次只使用5个字符的大模型参数,然后滑动,这样替换的参数就会少;window size选择为5,因为随着窗口的扩大,DRAM里面存储的参数要求在增大,但是替换的参数量其实没有边际上更小,所以用5来测试。
把同一个神经元点的参数储存在一起
直觉上就是把存储数据整合在同一行上,因为毕竟在计算的时候是同时使用的,没必要分两步进行吞吐计算量;
利用predictor把预测出可能是有用的,非0的部分从Flash Memory里面读出来。
优化在DRAM里面的数据存储使用
删除不需要的神经元参数,直接复制粘贴需要的,然后再添加,其实就是增加DRAM的使用效率。
结果
最后测试结果,在经过优化后运行大模型,可以缩短延迟时间,增加吞吐量。可以在苹果端使用大模型。