
“Implications of the inference scaling paradigm for AI safety” by Ryan Kidd
LessWrong (30+ Karma)
Shownotes Transcript
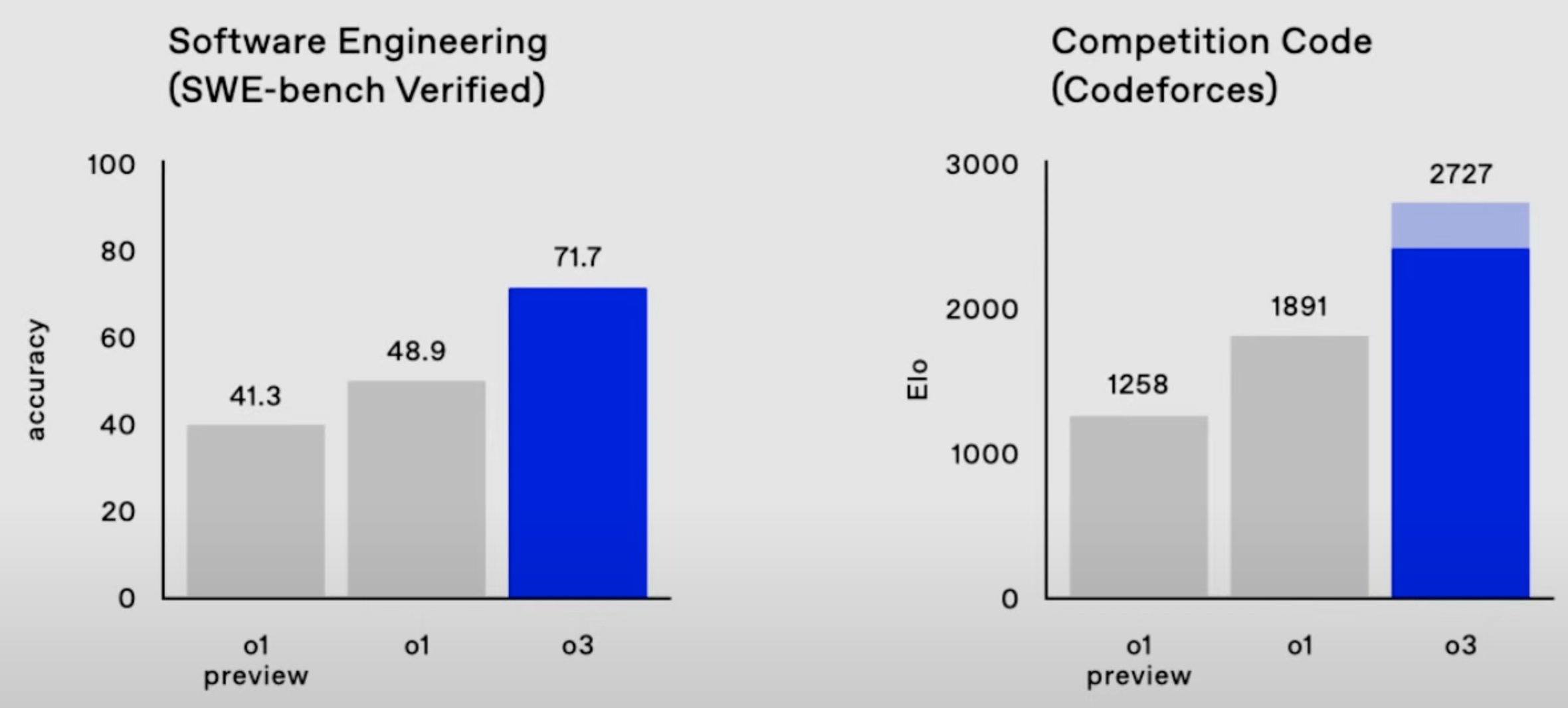
** Scaling inference** With the release of OpenAI's o1 and o3 models, it seems likely that we are now contending with a new scaling paradigm: spending more compute on model inference at run-time reliably improves model performance. As shown below, o1's AIME accuracy increases at a constant rate with the logarithm of test-time compute (OpenAI, 2024). OpenAI's o3 model continues this trend with record-breaking performance, scoring:
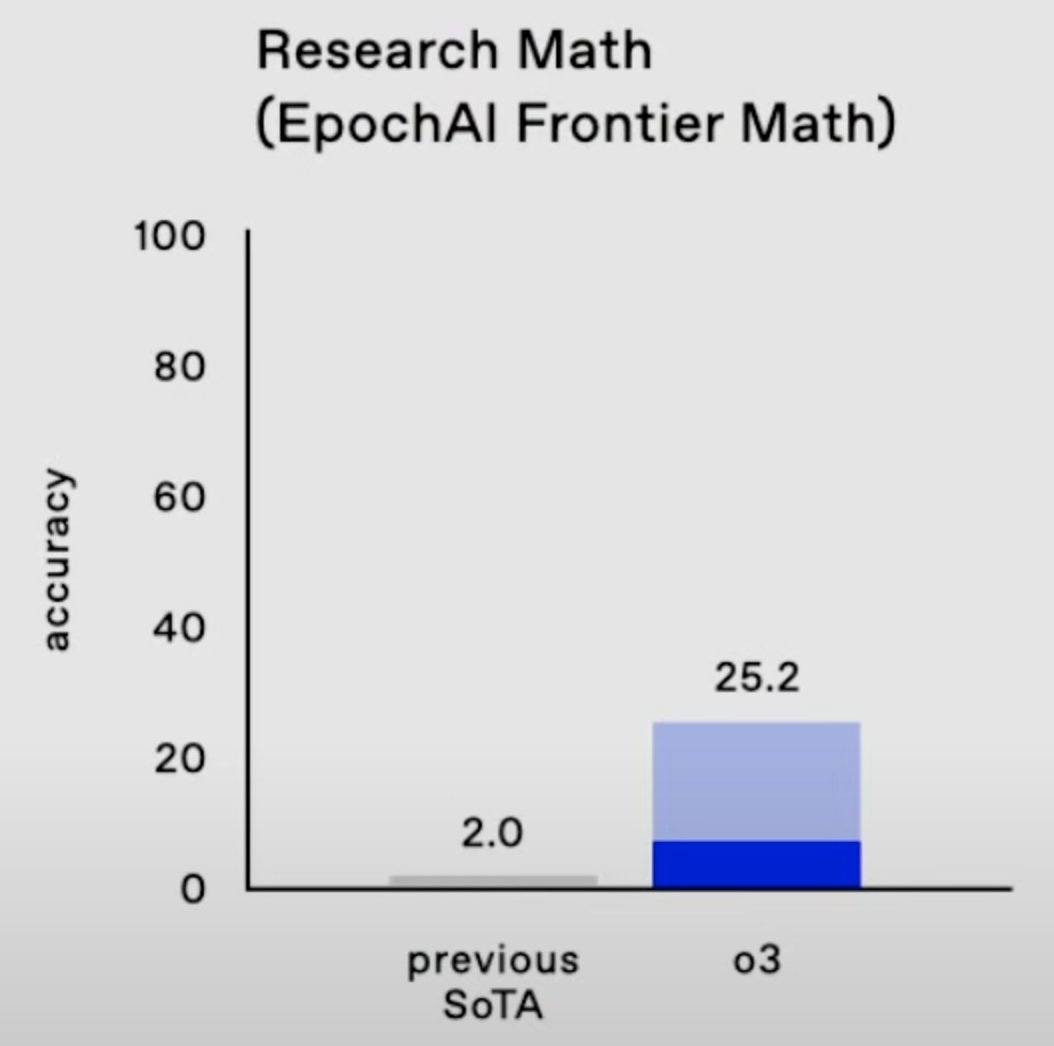
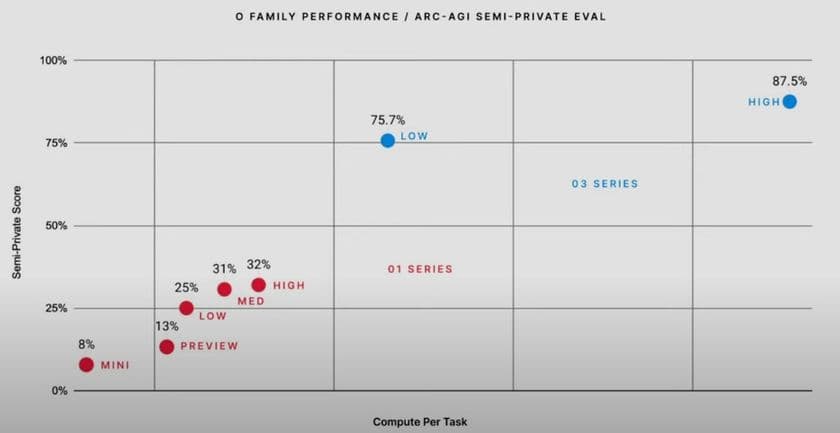
2727 on Codeforces, which makes it the 175th best competitive programmer on Earth; 25% on FrontierMath, where "each problem demands hours of work from expert mathematicians"; 88% on GPQA, where 70% represents PhD-level science knowledge; 88% on ARC-AGI, where the average Mechanical Turk human worker scores 75% on hard visual reasoning problems.
According to OpenAI, the bulk of model performance improvement in the o-series of models comes from increasing the length of chain-of-thought (and possibly further techniques like "tree-of-thought") and improving the chain-of-thought [...]
Outline:
(00:05) Scaling inference
(02:45) AI safety implications
(03:58) AGI timelines
(04:50) Deployment overhang
(06:06) Chain-of-thought oversight
(07:40) AI security
(09:05) Interpretability
(10:01) More RL?
(11:27) Export controls
(11:54) Conclusion
The original text contained 2 footnotes which were omitted from this narration.
The original text contained 7 images which were described by AI.
First published: January 14th, 2025
---
Narrated by TYPE III AUDIO).
Images from the article:
 )
) )
) )
) )
) )
) )
) )
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts), or another podcast app.
)
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts), or another podcast app.