
Deep Dive
- Acts as a personal research assistant
- Browses the web for about 5 minutes
- Outputs a research report
- Handles complex queries with multiple facets
Shownotes Transcript
现在大家都开始深入研究了。深度工作、深度学习、DeepMind。
如果2025年是代理的时代,那么2020年代就是深度学习的十年。虽然基于LLM的搜索技术已经存在了一段时间,例如Perplexity和SearchGPT,并且也存在像GPT Researcher这样的开源项目及其类似项目Open Deep Research,但商业化深度研究产品的区别在于,它们既是“自主代理”(大致意思是LLM决定工作流程中的下一步,通常涉及工具),又捆绑了经过定制微调的前沿模型,例如OpenAI的O3,或者像今天的嘉宾讨论的那样,是经过微调的Gemini版本。
自2月2日OpenAI发布Deep Research以来,人们的反响热烈异常。引述Jason Calacanis的话:引述结束。
我认为其质量与聘请一位优秀的博士级研究助理,然后让他完成为期一到两周甚至更长时间的任务相当。不同的是,Deep Research只需五到六分钟就能完成这项工作。引述Tyler Cowen的话:引述Ben Thompson的话:“Deep Research是科技领域最划算的产品之一”。
引述Sam Altman的话:“我粗略估计,它可以完成世界上所有具有经济价值任务的个位数百分比,这是一个了不起的里程碑。”此后,许多开源和闭源的类似产品纷纷涌现,试图复制这一成功,从Perplexity到X.AI昨天晚些时候发布的Grok 3。
在今天的节目中,我们欢迎Arush Selvan和Mukund Sridhar,他们是Gemini Deep Research的首席产品经理和技术主管,也是整个深度研究代理类别(一夜之间成为AI最新杀手级用例)的创始人。
我们从灵感到实现,提出了详细的问题,例如:为什么他们必须为它微调一个特殊的模型,而不是使用标准的Gemini模型;如何为它们运行评估;以及如何考虑用例的分布。Arush和Mukund还将作为嘉宾,于2月21日在纽约举行的AI工程师峰会上,在“代理工程”主题演讲。
这是我们最近一系列AI工程师峰会演讲嘉宾的最后一期,我们希望您和我们一样期待他们的演讲和研讨会。您可以注册在线直播,链接在节目说明中。峰会上见。保重。
大家好,欢迎收听Latent Space播客。我是Alessio,Decibel Partners的合伙人和首席技术官,与我一起的是我的联合主持人Swyx,Smol AI的创始人。大家好,今天我们非常荣幸地邀请到Arusha Mukund来到我们的演播室,他们是Deep Research团队,也就是Deep Research的元老团队。欢迎。
谢谢你们的邀请。是的,感谢你们来这里。我很幸运在Deep Research发布时成为早期测试者之一。我想说的是,我对它很感兴趣……我认为即使在去年年底,人们就已经说它是谷歌最令人兴奋的代理之一了。你们知道我们之前采访过来自Nobook LM团队的Ryza和Usama。我认为这是一个越来越明显的趋势……
Gemini和谷歌正在发布使用AI的有趣的面向用户的产品。所以,祝贺你们取得的成功。是的,很棒。非常感谢你们来到这里。是的,我很兴奋。是的,感谢你们来这里。我也很期待你们下周的演讲。显然,我们必须讨论它到底是什么,但我会在最后问你们。所以基本上,好的,我们已经打开了屏幕。也许我们先从高层次开始,对于那些还不知道的人来说。什么是深度研究?
当然。Deep Research是一个功能,Gemini可以充当您的个人研究助理,帮助您更深入地了解任何您想了解的主题。对于那些想要快速了解新事物的人来说,它非常有用。它的工作方式是:
获取您的查询,浏览网页约五分钟,然后输出一份研究报告供您查看并提出后续问题。这是第一次,你知道,某些事情需要大约五到六分钟来进行研究。所以这带来了一些挑战。例如,您希望确保在计算中花费的时间是用于用户想要的事情。因此,我们可以通过示例来讨论一些UX设计方法。然后,在……
网络非常分散,能够迭代地规划并在处理这些嘈杂信息时,本身就是一个挑战。是的,这就像谷歌第一次将自己自动化为搜索一样。就像你们应该是搜索方面的专家,但现在你们却像元搜索一样,在确定搜索策略。
是的,我认为至少我们认为这是两种不同的用例。有些事情,你知道,你确切地知道你在寻找什么。这仍然可能是,你知道,一个非常,你知道,可能最好的地方。我认为深度研究真正闪光的地方在于,你的问题有多个方面,你花了一个周末,你知道,只是打开了50到60个标签。很多时候我都放弃了。
我们想解决这个问题,并提供一个很好的起点。我们是否要启动一个查询,以便它同时运行,然后我们可以一起讨论?好的,这是一个我们喜欢的查询。
我们喜欢测试超级小众的随机事物,例如那些没有维基百科页面已经介绍的主题之类的东西,对吧?因为在那里,你会看到这个功能带来的最大提升。所以对于这个,我想出了一个查询。这实际上是Mokun的查询,他喜欢测试:帮助我理解美国和欧洲的牛奶和肉类法规有何不同。好的一点是,第一步实际上是它整理了一个您可以查看的研究计划,并且
所以这是它如何进行和执行研究的指南,对吧?所以这是一个相当明确的查询,但是,假设你来到Gemini,并且说,告诉我关于电池的信息,对吧?这个查询,你可以理解很多不同的意思。你可能想知道电池技术的最新创新。你可能想知道某种特定的电池化学成分。如果我们要花5到10分钟来研究某事,我们想了解一下,
你到底想在这里完成什么?其次,给你一个机会来引导研究的方向,对吧?因为如果你有一个实习生——
你问他们这个问题。他们做的第一件事就是问你一堆后续问题,然后说,好吧,所以帮助我弄清楚你到底想让我做什么。所以我们采用的方法是,我们想,为什么我们不只是让模型对研究查询进行第一次尝试,看看它将如何分解它,然后邀请用户参与他们想要如何引导这个过程。是的,很多时候当你……
尝试使用这样的产品时,你经常不知道要寻找什么问题或要寻找什么东西。所以我们非常刻意地做出了这个决定,而不是直接向用户询问后续问题,我们列出,嘿,这就是我要做的。这些是不同的方面。例如,这里可能是允许使用哪些添加剂以及它们有何不同,或者产品的标签限制等等。
这样做的目的是为了更多地告诉用户有关该主题的信息,并同时获得指导。同时,我们也征求了后续问题等等。所以我们是在一个联合会议中这样做的。这有点像可编辑的思维链。对,没错,没错。是的,我认为,你知道,我们正在和你讨论使用深度研究的最佳技巧。你的第一条技巧是编辑页面。只需编辑它即可,对吧?所以实际上,你可以进行对话式编辑。我们在这里放了一个按钮,只是为了引起用户的注意,说明你可以编辑这个。
哦,实际上你不需要点击。是的,实际上在早期测试中,我们发现没有人进行编辑。所以我们只是想,如果我们在这里放一个按钮,也许人们会……我承认我经常点击“开始”。我认为我们也看到了这种情况。大多数人都会点击“开始”。嗯,这就像,我试试看。是的,是的。好的。所以,我可以添加一个,添加一个步骤,你会看到它应该改进计划并向你展示一个新的建议。开始了。所以它添加了步骤七,在美国和欧盟中查找牛奶和肉类标签要求,或者你可以直接点击“开始”。我认为这仍然是一个很好的透明机制,即使用户不想参与,你仍然知道,好吧,至少我了解为什么我会得到我将要得到的报告,这很好。
然后,当它浏览网页时,Morgan,你也许可以解释一下它是如何浏览的。我们实时显示它正在读取的网站。是的,我先声明一下,我忘记解释角色了。你是产品经理,你是技术主管?是的。好的。是的。
对于那些不知道的人。哦,好的。也许我们应该先从这里开始,我想。是的。我们有时也会做彼此的工作,但大体上,这就是界限。是的。所以幕后实际发生的事情是……
我们提供了一个研究计划,这是一个合同,并且已经被接受。但是,如果你查看该计划,你会发现有些事情显然是可以并行处理的。因此,模型会找出它可以并行开始探索的子步骤,然后它主要使用两种工具。它能够执行搜索,并且能够深入到特定网页中。通常情况下,它会并行开始探索事物,但是
这还不够。很多时候,它必须根据找到的信息进行推理。因此,在这种情况下,其中一项搜索可能导致欧盟委员会禁止使用这些添加剂,它想要检查FDA是否也这样做。对。因此,能够读取上一轮的输出,并根据该输出决定下一步做什么,我认为这是关键。否则,你就会有不完整的信息,你的报告就会变成一些高级别的要点。所以我们想超越这个蓝图,并真正弄清楚这里有哪些关键方面。所以,是的,所以这个过程会迭代地进行,直到模型认为它已经完成了所有步骤。
然后我们进入分析模式。在这里,各个来源之间可能存在不一致之处。你会为报告制定一个提纲,开始生成草稿。该
模型会通过自我批评来修改它,你知道,以最终确定提示,最终确定报告。这大概就是幕后发生的事情。网站的初始排名是什么?所以当你第一次启动它时,有36个网站。你如何决定从哪里开始,因为它听起来像,你知道,最初的网站也承担了很多权重,因为它们会影响后续的内容。是的。所以,在初始阶段发生的事情,再次强调,这不像……
这不是我们强制执行的。这主要是模型做出的选择。但是,通常情况下,我们看到模型正在探索研究计划中提出的所有不同方面。因此,我们能够对要探索的不同主题有一个广度优先的了解。至于要深入研究哪些主题,我认为这实际上取决于每次搜索时,模型都会对页面有一些了解,然后讨论
取决于它的哪些部分。有时存在不一致之处,有时只是部分信息。这些就是它会深入研究的内容。是的,你可以持续地迭代搜索和浏览,直到它感觉已经完成了。是的,我正在尝试思考我将如何编写这个代码。一个简单的问题是,你认为我们可以使用Gemini API来做到这一点吗?或者你们有一些我们无法复制的特殊访问权限吗?你知道,就像如果我用所谓的搜索、双击等等来建模这个。是的,我认为我们没有特殊的访问权限,它基本上是相同的模型,当然,我们有自己的后期训练工作,你们也可以,你知道,你可以从基础模型进行微调等等,我不知道我们能不能做这个微调
好吧,如果你使用我们的Gemma开源模型,你可以进行微调。是的。所以我不认为有什么特殊的访问权限,但是对我们来说,很多工作是,
首先定义这些,哦,需要一个研究计划,以及你将如何呈现它?然后进行大量的后期训练,以确保它能够始终如一地很好地完成这项工作,并且具有很高的可靠性和所有这些。好的,所以带有深度研究功能的1.5 Pro是1.5 Pro的特别版。是的。所以它不是纯1.5 Pro。它是一个后期训练的版本。这也解释了为什么你不能只是切换到2.0 Flash,然后就……是的。对。好的。
是的。但是我的意思是,我认为你们有数据,而且,你知道,这应该是可行的。是的。仍然存在排名的问题。是的。对。就像,哦,看起来你已经完成了。是的。是的。我们完成了。我们可以看看。是的。所以让我们看看。它整理了这份报告,它所做的是,它分解了,从牛奶法规开始,然后它看起来可能进一步深入到肉类中,然后大致
介绍了美国如何处理监管牛奶这个问题,进行比较,然后,你知道,介绍欧盟。然后,是的,就像我说的那样,深入到肉类生产中。然后它还会,好的一点是,它会对为什么存在差异进行推理……
我认为这里真正酷的地方在于,它显示了美国和欧盟规范食品的方式之间存在哲学差异。因此,欧盟采取预防措施。因此,即使关于某事存在不确定的科学证据,它仍然更倾向于禁止它。而美国则采取被动的方式,即允许某些东西,直到它们被证明是有害的,对吧?所以,这很好,因为你也会……
从它所整理的内容中获得二阶见解。所以是的,这很好。阅读和理解所有内容需要几分钟时间,这使得播客期间有一段安静的时间,我想。但是是的,这就是它目前的样子。是的。然后从这里,你可以……
继续进行通常的聊天和迭代。所以这更多的是,如果你要……你知道,与其他平台进行比较,它有点像熵论的工件,或者像聊天,你会是画布,就像……
你在一侧有文档,在另一侧有聊天,你正在处理它。是的,这是我们思考过的事情。我们认为的一件事是,你的学习旅程不应该在第一份报告之后就停止。所以实际上你可能想要做的是,在阅读时,能够提出后续问题,而无需来回滚动。并且大体上……
有几种不同类型的后续问题。一种类型是,也许你想要一个这里没有的事实,但它可能已经被捕获为它所做的网页浏览的一部分。对。所以我们实际上将所有内容都保存在上下文中,就像它读取的所有站点都保留在上下文中一样。因此,如果缺少信息,它可以获取该信息。然后另一种类型是,好的,这
很好,但你实际上想开始更多深入的研究。你可能会说,例如,我还想比较欧盟和亚洲在如何规范牛奶和肉类方面的情况。为此,你实际上希望模型能够像,好吧,这足够不同,我想进行更多深入的研究来回答这个问题。我不会在我的已浏览内容中找到这些信息。
第三种实际上是你可能只想更改报告。也许你想压缩它,删除部分内容,添加部分内容,并实际迭代你得到的报告。因此,我们大体上基本上试图教模型能够完成所有这三项任务。并且并排格式允许……
用户更容易做到这一点。是的。所以作为一名产品经理,那里有一个打开文档按钮,对吧?你如何考虑你应该在这里构建的内容与压缩和内容应该是一个谷歌文档?是的。Bot扩展是不同的。这就像一个很棒的编辑器。有时你只想直接编辑内容。
现在谷歌文档也在侧边栏中嵌入了Gemini。因此,我们越能帮助它成为你在整个谷歌生态系统中的工作流程的一部分,就越好,对吧?我们注意到的一件事是,人们非常喜欢那个按钮,并且非常喜欢导出它。这也是永久保存它的好方法。
当你导出所有引文时,事实上,我现在就可以运行它,继续进行,这也非常好。Gemini扩展是一个不同的功能。这实际上是围绕Gemini能够从其他谷歌服务中获取内容以告知答案。这实际上是我们两人在团队中共同完成的第一个功能。实际上是在Gemini中构建扩展。我认为现在我们有很多不同的谷歌应用程序,以及我认为Spotify和一个
和几个,我不知道我们是否还有三星应用程序。谁想要Spotify?我一直在想这个问题,我喜欢Spotify。谁想在他们的深度研究中使用它?在深度研究中,我认为较少,但是,有趣的是,我们构建了扩展,我们没有,我们不确定人们将如何使用它。很多人正在用它们做非常有创意的事情。很多人只是在做他们在谷歌助理上喜欢做的事情。
Spotify就像一个巨大的,像在旅途中播放音乐一样,是一个巨大的价值。哦,它控制Spotify?是的。这不是深度研究。对于深度研究,你显然会使用,是的,是的,是的。但是除此之外,是的,就像你可以,你可以让Gemini去。是的。你们有YouTube地图和搜索Flash Thinking实验性应用程序。最新、最长的模型名称已经发布。是的。
但是,是的,我认为Gmail是一个显而易见的选择。日历是一个显而易见的选择。没错。那些我想要。Spotify。足够了。是的。显然,随意深入了解你们其他的工作。我知道你们不仅仅是在做深度研究,对吧?
但是,你知道,我们只是专注于深度研究。我实际上在第一次运行后要求修改,当时我想,哦,你停了。就像,我实际上想让你继续。这些其他的东西呢?然后继续修改它。所以它真的感觉有点像副驾驶类型的体验,但更像是一个代理……
我认为这很酷。是的,其中一个挑战是,我们目前让模型根据你的查询来决定这三个类别中的哪一个。所以这里有一个界限,就像这些事情中的一些,取决于你想深入到什么程度,你可能只需要一个快速的答案,而不是……
开始另一个深入的研究。即使从UX的角度来看,我认为该面板也允许这种概念,即并非每个后续操作都需要花费你五分钟的时间。现在,它不会进行任何后续操作。它会进行后续搜索吗?它总是会进行吗?这取决于你的问题。由于我们可以使用非常长的上下文模型,
我们实际上在整个舞蹈中保留所有研究材料。因此,如果它能够在已找到的内容中找到答案,你将获得更快的回复。是的,否则它只会返回到规划阶段。是的,是的。关于你提到的上下文,我有一些后续问题。一个问题是,你们有HTML到Markdown的转换步骤吗?
或者你们只是使用原始HTML?你们不可能使用原始HTML,对吧?我们有两个版本,对吧?所以,模型正在变得,就像每一代模型都越来越擅长对这些表示进行本地理解。我认为Markdown步骤肯定有助于,你知道,有很多噪音,就像你可以想象到的纯HTML一样。JavaScript、Win CSS。没错,没错。所以是的,当这样做有意义时,我们不会人为地让模型难以处理。但是有时这取决于我们获得的访问类型。例如,如果有一个嵌入式片段是HTML,我们希望模型能够处理它。是的,还没有视觉功能,但是……
但是目前还没有视觉功能。我问这些问题的原因是我也做过同样的事情。就像我没有做过视觉方面的工作一样。是的,所以视觉方面棘手的地方在于,我认为模型正在变得越来越好,尤其是在过去六个月中,能够本地执行VQA之类的事情。但是挑战在于权衡,即必须,你知道,实际渲染它等等。增加的延迟与你获得的附加值之间的权衡。你们有延迟预算……
是的,是的,是的。这是真的。在我看来,你会看到真正差异的地方是,我不知道,一小部分尾部,尤其是在这种开放域设置中,如果你只看看人们提出的问题。肯定有一些用例非常有意义,但我仍然觉得它不在主要用例中,我们会在到达那里时再做。经典的例子是,它是一个JPEG,其中包含一些重要的信息,你无法触碰它。是的。
好的,然后另一个技术性的后续问题是,你们有100万到200万个令牌的上下文。它是否曾经超过200万?你们在那里会怎么做?是的,我们在去年某个时候遇到了这个挑战,当时我们说,当我们开始连接这个多轮对话时,我们说,嘿,
让我们看看团队中的某个人可以使用DR多长时间,你知道吗?是的。你能问出什么最具挑战性的问题,需要最长时间?是的。不,我们也一直在询问,例如,在这里你可以说,嘿,我还想比较一下,好的,所以你肯定会超过它。是的。是的。我们也有,我们有检索机制,如果需要的话。所以我们,我们,
本地尝试使用尽可能多的可用上下文,除此之外,你知道,我们有一个机架设置来弄清楚好的,这些都是内部的内部技术,是的,好的,是的,在将内容放在上下文中与RAG之间有什么区别?当我在新加坡时,我去谷歌云……当我在新加坡时,我去谷歌云团队,他们
谈论Gemini加接地,Gemini加搜索是否类似于Gemini加接地?或者,人们应该如何看待不同方面的,例如,我正在进行检索和数据处理,与我正在使用深度研究,与我正在使用接地。有时标签很难……
是的,我可以。让我尝试回答问题的第一个部分。第二个部分,我不太确定接地服务。所以至少我可以谈谈问题的第一个部分。所以我想你是在问像能够,什么时候你会做RAG,而不是依赖于长上下文?我认为我们都理解这一点。我更好奇的是,从产品的角度来看,你什么时候决定RAG。
做RAG,而不是像这样,你不需要,你知道,你是否可以通过将所有内容都放在上下文中来获得更好的性能?RAG棘手的地方在于,它确实运行良好,因为很多这些事情都在做余弦距离,就像点积之类的东西。当你的查询端有多个不同的属性时,这就会变得具有挑战性。点积实际上并不太好。我想说,至少对我来说,这是我避免RAG的指导原则。这是一个。第二个是,我认为每一代模型都像最初的几代模型一样,即使它们提供了长上下文,它们的性能随着上下文的增长而下降,你会看到某种程度的下降。但是我认为随着新一代模型的出现,它们非常好,即使你
继续填充上下文,也能够提取出这些非常细微的信息。所以我认为这两个,至少对我来说,是……只是为了补充一下,我认为就像我们使用的简单经验法则一样,
如果这是用户很可能会提出大量后续问题的最新一组研究任务,则应该在上下文中进行。但是,如果事情已经过去了10个任务,那么如果这些内容在RAG中是可以的,因为用户不太可能需要……你需要在当前正在讨论的内容和你10轮之前询问的内容之间进行非常复杂的比较。所以
因此,这只是一个我们遵循的经验法则。从用户的角度来看,最好是开始一个新的研究,而不是扩展上下文吗?是的,我认为这是一个好问题。我认为,如果这是一个相关的主题,那么继续这个线程是有好处的,因为你可以,模型,因为它在内存中,可以计算出,哦,我发现了这个利基的东西,关于,我不知道,在这种情况下,牛奶的规定。在美国,让我检查一下你的后续国家或地方是否也有类似的东西。所以,你可能没有抓住这些事情,如果你开始了一个新的线程。所以我认为这真的取决于
用例,如果有一个自然的进展,你感觉这就像是一个连贯的项目的一部分,你应该继续使用它,我的后续回合将是,哦,我只是要去寻找夏令营之类的东西,那么是的,我认为这应该没有区别,但我们并没有真正地,你知道,推动这一点,并测试了我们大多数测试的这一方面,就像更自然的转变一样,你如何评估深度研究
哦,天哪。是的,这是一个难题。我认为输出空间的熵太高了。人们喜欢自动评分器,但这带来了它自己的一套挑战。因此,对我们来说,我们有一些我们可以自动生成的指标,对吧?例如,当我们移动时,当我们进行后期训练并拥有多个模型时,
我们想确保某些统计数据的分布,例如,在规划上花费了多长时间,它在某个开发集上进行了多少迭代步骤。如果你看到分布发生很大的变化,这就像一个早期信号,表明某些事情发生了变化。这可能是好是坏。
所以我们有一些这样的指标,我们可以自动计算。因此,每次你有一个新版本时,你都会在测试套件的案例中运行它,并查看它需要多长时间?是的,所以我们有一个开发集,我们有一些我们可以检测到的某种自动指标,就端到端的行为而言。例如,研究计划有多长?我们是否喜欢,一个新的模型是否会产生更长的、更多的步骤?只是字符数。像研究计划的情况下的步骤数。在计划中,它可能是这样的,
就像我们谈论的,它如何基于之前的搜索迭代地进行规划。在某个开发集上,平均需要多少步骤?所以有一些这样的事情你可以自动化,但是除此之外,
有自动评分器,但我们肯定做了很多人工评估。在那里,我们已经与产品一起定义了我们关心的某些事情,并且对这些事情非常有主见。它是否全面?它是否完整?像基础性这样的事情。所以这是一个混合的两个属性。还有一个挑战,但我将让你。这是哪里其他的挑战?
有时你只需要让你的项目经理审查示例。是的,完全正确。对于延迟……所以你是人工阅读器。人工阅读器。但总的来说,我们为评估问题所做的是,我们试图考虑一个人可能使用此功能的所有方法
我们想出了我们所说的用例本体。是的。我们真正想做的是,比如远离垂直领域,比如旅行或购物之类的,而是真正深入到人们正在进行的底层研究行为类型是什么?所以有……
一端是查询,只是你正在进行非常广泛但肤浅的查询,对吧?像购物查询就是这样的一个例子,或者像,我想找到一个完美的夏令营。我的孩子们喜欢足球和网球。你真的只想找到尽可能多的不同选择,并探索所有可用的不同选择,然后综合一下,好的,每个选择的 TLDR 是什么?就像你打开很多、很多 Chrome 标签页,但随后
需要在某个地方记下有吸引力的东西。在光谱的另一端,你知道,你有一个特定的主题,你只想深入研究这个主题,并真正理解它。中间还有各种各样的点,对吧?围绕着,好吧,我有一些选择,但我想比较它们,或者,是的,我不想深入研究一个主题,但我想涵盖更多一点的主题。因此,我们对不同的
研究模式开发了这种本体,然后为每一个模式提出了符合该模式的查询,然后这就是评估集,通过它,我们然后运行人工评估,并确保我们正在努力
在所有这些方面做得很好。是的,你提到了三件事。是字面上的三件事,还是 20 件事情中的三件事?类比有多宽?我基本上只是告诉了——完整的集合?是的,我告诉你极端情况,对吧?极端情况,好的。是的,然后我们有几个中间点。所以基本上,是的,从非常广泛和肤浅的东西到非常具体和深入的东西。我们实际上不确定光谱的哪一端用户会真正产生共鸣。然后最重要的是,你还有这些东西的复合物,对吧?所以你可以有这样的事情
你想要制定一个计划,对吧?就像一个很好的例子,就像,我想在,你知道,里斯本计划一场婚礼,我,你知道,我需要你帮我做这 10 件事,对吧?所以这就像一个启用了研究的项目。对。所以它需要研究规划者、场地和餐饮,对吧?所以当你开始组合这些不同的底层本体类型时,就会有某种复合物,对吧?
所以我们也在考虑这一点,当我们尝试将我们的评估集放在一起时。你允许或设计的最大对话长度是多少?我们对可以进行的回合数没有任何硬性限制。我要说的一件事是,大多数用户现在不会深入研究。是的。这可能只是因为需要一段时间才能适应。然后随着时间的推移,你开始越来越深入地推动它。但就像现在我们没有看到很多用户一样。
我认为你直观地呈现它的方式表明,当你创建文档时,你就会停止。对。所以你实际上并没有真正鼓励,UI 并没有像项目那样鼓励持续的聊天。对。我认为我们肯定可以在 UX 方面做一些事情,基本上邀请用户说,嘿,这是起点。现在让我们一起继续前进。你想探索其他什么地方?是的。
所以我认为我们肯定可以做一些探索。我认为就深度而言,我不知道,我们看到内部人员真的把这件事推到了很多方面。我认为随着时间的推移,我认为另一件事将会改变的是,人们会发现使用深度研究的不同方法。例如,对于婚礼策划来说,这并不是当我们告诉人们这个产品时,首先想到的事情之一。
所以这是我认为的另一件事,当人们探索并发现这可以做各种不同的事情时。其中一些可以自然地导致更长的对话。即使对我们来说,对吧,当我们自己尝试这个产品时,我们看到人们以我们之前从未想到过的方式使用它。所以这是因为这有点新。我们不知道……
像,用户会等五分钟吗?他们会尝试什么样的任务,类似于需要五分钟的任务?所以我们的主要目标不是专门研究某个垂直领域或针对某种类型的用户。我们只是想把它交给,比如,我们有这个忙碌的父母角色和各种不同的用户资料,看看人们尝试用它做什么,并从中学习更多。本体的
DR 用例与 Google 主要产品用例有何关联?所以你提到购物是一个本体,对吧?还有 Google 购物。是的。对我来说,这听起来比去 Google 购物并查看商品墙要好得多。你们如何在内部合作以确定 AI 的去向?
是的,这是一个好问题。所以当我提到购物时,我试图从根本上分析一下确切的行为是什么。这实际上是关于,我称之为选项探索,就像你只想能够看到,无论你是在为夏令营购物,
还是为产品购物,还是为奖学金机会购物。这是一种相同的行为,就像,我需要从一个大型的……我需要筛选大量信息来为我策划一堆选项。所以这就是我们试图提炼的东西,而不是像把它看作一个垂直领域。但是是的,Google 搜索很棒。如果你想要非常快速的答案,你对像,我知道我想要什么有很高的意图。
并且你想要超级最新的信息,对吧?
我仍然有点喜欢 Google 购物,因为它就像多模式的。你可以看到最好的价格等等。我认为创造良好的购物体验很难,尤其是在你需要查看商品的时候。如果我正在购买鞋子,并且我不想使用深度研究,因为我想……我不想看鞋子的样子。但是如果我正在购买像 HVAC 系统这样的东西,那就太好了。就像我不在乎它是什么样子,或者我甚至不知道它应该是什么样子。而我使用深度研究没问题,因为我真的很想了解规格,以及
它到底是如何工作的,以及电压等级等等,对吧?所以,就像,我还需要查看知道如何安装每个 HVAC 系统的承包商。所以我会说,当涉及到购物时,我们真正闪光的地方是那些,那种光谱的末端,就像,
它更复杂,而且它看起来的样子不那么重要,就像,它可能在购物的消费方面不那么重要。我还观察到的一件事是关于,我猜,指标或你提供的价值的沟通。这也涉及到延迟预算,我认为对于研究代理来说,花费更长时间并被认为更好是一种普遍的激励。
人们会说,哦,你正在为我搜索 70 个网站,你知道,但其中 30 个是不相关的。你知道,就像我现在感觉我们正处于蜜月期,你可以通过所有这些。但效率低下实际上对你有好处,因为,你知道,人们只关心数量,而不是质量。对。
对。所以他们会说,哦,这件事花了我一个小时。就像它做了很多工作一样,或者它很慢。这对我们来说非常违反直觉。所以实际上,我第一次意识到你说的是当我与 Jason Calacanis 谈话时,他说,你实际上是在 10 秒钟内给出答案,然后让我等待余额吗?是的。我们之前没有预料到。
人们会真正重视它所做的工作。因为……你实际上很担心。我们真的很担心。我们就像,我记得,我们实际上构建了两个版本的深度研究。我们有一个铁杆模式,需要 15 分钟。然后我们实际发布的是一个需要 5 分钟的东西。我甚至去了 Eng,我说,顺便说一句,必须有一个硬性停止。它永远不能超过 10 分钟。是的。因为我认为在那一点上,用户会直接放弃。但是……
但令人惊讶的是,情况并非如此。而且情况正在朝着另一个方向发展。因为当我们至少在 Assistant 和其他 Google 产品上工作时,指标一直是,如果你提高了延迟,那么所有其他指标都会上升,比如满意度上升,保留率上升,所有这些,对吧?所以当我们提出这个建议时,它就像,等等,与所有 Google 正统观念相反,我们实际上要放慢一切速度。
我们将希望用户仍然坚持下去。并非故意。是的,我认为这取决于权衡。你得到了什么回报?等待的回报是什么?从工程/建模的角度来看……
它只是权衡推理、计算和时间来做两件事,对吧?要么探索更多,要么更完整,要么验证你可能已经知道的事情。由于它像一个光谱,我们不声称已经找到了完美的位置,我们必须从某个地方开始,我们正在尝试查看……可能有一些情况,你实际上比其他情况更关心验证。在一个理想的世界里,根据查询和对话历史,你知道那是什么。
所以我认为,是的,它基本上可以归结为这三件事。从用户的角度来看,我是否获得了正确的附加值?从工程/建模的角度来看,我们是否正在使用计算来有效地探索,并验证和深入研究初始步骤中模糊或不确定的内容?关于更多网站的另一点,我认为,同样,它也与权衡有关。有时你想要探索网站
在你缩小你想要深入研究的来源或主题之前,在早期探索更多。所以这是其中之一,如果你看一下,至少对于大多数查询来说,深度研究在这里的工作方式是,它最初会广泛地进行。如果你看一下网站的种类,它是时候探索我们在研究计划中衡量的所有不同主题了。
然后你会看到网站的选择在一个特定的主题或它遇到的特定实体上变得越来越窄。所以这就是数字波动的大致方式。所以我们不会故意做任何事情来降低它,或者,你知道,尝试……是否有一个明确的切换来验证数量与搜索数量会很有趣?是的。
我认为是这样。我认为用户总是会点击那个切换。我担心……最大化一切。是的,如果你给出一个最大功率按钮,用户总是会点击那个按钮,对吧?所以问题来了,为什么你不只是……
从产品 POV 的角度决定正确的平衡点。OpenAI 对此有一个预览,我认为是 Anthropic 或 OpenAI,并且有一个此模型路由功能的预览,你可以选择智能、廉价和速度。但是它们都是 0 到 1 的值。所以你只需要为所有内容选择一个。对。
显然,他们会做归一化的事情,但用户总是想要一个,对吧?我们讨论过这一点。如果我戴着我的纯用户帽子,我什么也不想说。我带着一个查询来,你把它弄清楚。有时我觉得会有,根据查询,例如,如果我问,嘿,美联储的加息如何影响中产阶级的收入?它传统上是如何发生的?是的。
这些事情,你想要非常准确,并且你想要对这方面的历史趋势非常精确,等等,等等。而当你说,嘿,我试图在我的附近找到一些企业来庆祝我的生日之类的事情时,就会有更多一点的余地。所以在理想情况下,我们会根据对话历史和主题来计算这种权衡。
我认为我们作为研究界还没有达到这个水平。这是一个很有趣的挑战。所以这让我有点想起了笔记本 LM 方法。Riza,她也问了 Riza 这件事,她说,是的,人们只想点击一个按钮并看到魔法。是的,就像你说的,你每次都点击开始,对吧?你不会,大多数人甚至不想添加计划。所以,好的。关于这一点,如果你想要反馈的话,我的反馈是……
我仍然是 Devin 的拥护者,从某种意义上说,Devin 会在制定计划的同时向你展示计划。你可以说,嘿,计划错了。在我仍然在工作的时候,我可以与它聊天。你可以实时更新计划,然后从计划中选择下一个项目。我认为它是静态的,对吧?就像你在制定计划时,我无法聊天。
这很正常。Bolt 也有这个。这是最默认的体验。但我认为你永远不应该锁定聊天。你应该始终能够与计划聊天并更新计划,而计划调度程序,无论你有什么后台编排系统,都应该只从列表中选择下一个作业。那将是我的两分钱。特别是如果我们花更多时间进行研究,对吧?因为就像现在,如果你观看我们刚刚做的那个查询,它在几分钟内就完成了。所以你的机会,你插话的机会实际上是,或者它在几分钟后离开了研究阶段。是的。
所以你插话和引导的机会较少。但尤其是在你可以想象一个这些事情需要一个小时的世界,对吧?你正在做一些非常复杂的事情。那么是的,就像你的实习生会完全来和你核对,说,这是我发现的。这是我遇到的计划中的一些障碍。给我一些关于如何改变它或如何改变方向的指导。你会和他们一起做这件事。所以我完全会看到,特别是随着这些任务越来越长,
我们实际上希望用户参与更多,以创造良好的输出。我想 Devin 必须这样做,因为其中一些工作需要几个小时。对。所以,是的。而且它很普遍,因为它收取的是按小时收费。
哦。所以他们赚的钱越多,速度越慢。我们考虑过吗?我之所以指出这一点,是因为每个人都像,哦,我的上帝,这需要几个小时。它为我自主地工作了几个小时。他们说,好吧,这很好。但就像,这是一个蜜月期。就像在某个时候我们会说,好吧,但你知道,它非常慢。是的。
其他任何事情,比如,我的意思是,显然在 Google 内部,你们有很多其他的计划。我相信你,就像,坐在 Nopal Gallim 团队附近。从发布你
AI 产品中获得的任何经验教训?他们是非常棒的人。就像他们非常友善、友好的想法一样,就像人们一样,我相信你遇到过他们,你像与 Razer 一样意识到这一点。所以他们实际上一直是非常非常酷的合作者,或者只是像可以互相交流想法的人一样。我认为我发现真正鼓舞人心的一件事是,他们只是选择了一个问题,事后诸葛亮,但在之前,就像,嘿,我们只想为你构建一个完美的 IDE 来工作,并且能够上传文档并询问有关它的问题,并使其真正变得非常好。
我认为我们绝对受到了他们能力的启发,他们的愿景就像,让我们选择一个简单的问题,真正地解决它,做得非常好,并且对它应该如何工作有自己的看法,并希望用户也能产生共鸣。这绝对是我们试图学习的东西。另外,他们也非常擅长,你知道,也许摩根,你想在这里插话,只是从 Gemini 1.5 Pro 中提取最多的东西。
他们非常友好地分享了他们关于如何做到这一点的想法。是的,我认为你学习了一些东西,就像当你试图完成这些产品的最后一步以及任何给定模型的陷阱时一样。所以是的,我们肯定有良好的关系,并且分享笔记,我们也在为其他产品做同样的事情。你永远不会合并,对吧?只是不同的团队。
他们是不同的团队。所以他们就像一个组织中的实验室一样。这项任务的目的是真正探索各种不同的赌注,并探索可能的可能性。尽管我认为 Nopal Gallim 现在有一个付费计划。是的。而且它与我们的计划实际上是一样的。所以它就像……它不仅仅是实验室,这就是我的意思。它不仅仅是实验室。因为,我的意思是,是的,理想情况下,你希望事情毕业并留下来。但希望我们所做的一件事是,比如不……
创建不同的偏差,而是像,嘿,如果你支付 AI 的费用,是的,无论如何,你都会得到所有东西。关于向其他人学习呢?显然,我的意思是,OpenAI 的深度研究实际上是相同的名称。我相信有很多,你知道,争议。你从其他人尝试构建类似工具中学到了什么吗?比如,你对人们可能做错的事情以及他们应该如何做得不同有什么看法吗?从外部来看,很多这些产品看起来都一样。
要求进行研究,然后获得研究结果。但显然,当你构建它们时,你会更多地了解细微之处。当我们构建深度研究时,我认为有一些事情我们做了一些不同的赌注,关于它应该如何工作。好的一点是,其中一些实际上是我们认为是正确方法的地方。所以我们觉得代理应该在研究方面保持透明。
提前告诉你,特别是如果他们要花一些时间,他们要做什么。所以这就是我们展示在卡片中的研究计划。我们真的想在这个产品中非常积极主动。所以当它正在浏览时,我们想向你展示它正在实时阅读的所有网站,让你非常容易在它浏览时双击这些网站。
第三件事是,你知道,把它放在一个并排的工件中,这样你就可以理想地轻松阅读和提问。好的一点是,你,随着其他产品出现,你会看到这些想法也出现在该产品的其他迭代中。所以我绝对认为这是一个空间,在这个空间中,行业中的每个人都在互相学习。
好主意会被复制和建立。所以,是的,我们将肯定继续迭代,并不断关注我们的用户,看看我们如何才能让我们的未来变得更好。但是是的,我认为,我认为这就像,这就是行业的工作方式。就像每个人都会看到好主意,并想要复制和从中构建一样。
在模型方面,OpenAI 有 O3 模型,它无法通过 API 获得,完整的模型。你已经尝试过使用两个模型了吗?就像,这是一个很大的飞跃,还是很多工作都在后期训练上?是的,我会说敬请期待。当然,它目前运行在 1.5 上。新一代模型,特别是这些思维模型,它们解锁了一些东西。所以我认为其中一个显然是在像分析性思维方面,比如在数学、编码和这些类型的事情方面。但也有这个概念,你知道,当他们产生想法并在采取行动之前进行思考时,他们天生就具有能够批判他们采取的部分步骤等等的能力。所以是的,我们肯定正在探索多种不同的选择,以更好地
为我们的用户创造更好的价值,因为我们交易。是的。我觉得这里有一点推理时间计算的混淆,就像,一,你可以在思维模型中进行推理时间计算。对。然后二,你可以通过搜索和推理来进行推理时间计算。我想知道这是否会妨碍,就像你可能已经测试了思维加深度研究,并且
如果思维实际上做了一些验证,所以可能节省了一些时间,或者它试图从其内部知识中提取太多信息,然后因此搜索较少,你知道,就像它是否相互影响一样?是的,不,我认为这是一个非常好的指出。这也回到了用例的类型。我之所以提出这一点,是因为,
我可以从模型内存中告诉你一些事情,去年美联储进行了 X 次更新等等,但除非我找到了来源,否则它将是……幻觉。是的,就像,一个是幻觉,或者即使我做对了,作为用户,我也会非常警惕,
除非我能像获取 .gov 网站的来源等等。对吧?所以这是一个挑战。就像有一些事情你可能不会最优地花费时间去验证,即使模型像
这是一个非常普遍的事实,模型已经知道,并且能够进行推理。在尝试利用模型内存与能够将此内容放在某种来源之间取得平衡是具有挑战性的部分。我认为,正如你正确指出的那样,对于思维模型来说,这一点更为明显,因为模型知道的更多。他们能够仅仅通过推理就能得出更多二阶见解。从技术上讲,他们知道的并不多,他们只是更多地使用了他们的内部知识,对吧?是的。
是的,但就像,例如,像数学这样的东西。我明白了。他们经过后期训练可以更好地进行数学运算。是的,我认为他们只是,他们在数学方面做得比以前更好。是的,我的意思是,显然推理是一个非常令人感兴趣的话题,人们想知道工程最佳实践是什么。就像,我们认为我们知道如何更好地提示它们,但是……
但是与它们一起进行工程设计,我认为也很未知。同样,你们将成为第一个弄清楚的人。是的,绝对是令人兴奋的时代。别有压力,Mokka。如果你有技巧,请告诉我们。当我们讨论技术元素和技术弯曲时,我对深度研究技术堆栈的其他部分感兴趣,这些部分可能值得一提。你通常解决的任何难题?
是的,我认为迭代规划是一个以可推广的方式进行的。是的,这是我最担心的问题。就像你不想走这条路,能够针对每个领域或每种类型的难题来教如何迭代地进行规划一样。就像,即使在返回本体的过程中,如果你必须教他们所有人。对于每一种本体类型,如何提出这些规划痕迹,那将是一场噩梦。所以尝试以一种超级数据高效的方式来做到这一点,通过,你知道,利用很多像,模型内存,以及像,当你处理像这些模型的产品端时,有一个非常棘手的平衡,知道如何进行后期调整,而不会丢失它在预训练中知道的东西,基本上不会以最简单的方式过度拟合,我猜。但是是的,所以技术,他们的数据增强在那里,以及多个实验来调整这种权衡。我认为这是一个挑战。是的。
在编排方面,这基本上是你正在启动一个作业。我是一个编排狂热者。那么你如何做到这一点呢?是的,这是一个内部子工具?是的,所以我们为深度研究构建了这个异步平台,它基本上是,在我们之前的大多数交互都是同步的。是的。是的。
是的,我认为迭代规划以一种可泛化的方式来做。是的,这是我最担心的问题。就像你不想走上必须针对每个领域或每种类型的难题来教导如何迭代规划的道路。就像回到本体论中一样,如果……
如果你必须教模型针对每种类型的本体论如何制定这些规划轨迹,那将是一场噩梦。因此,尝试以一种超级数据高效的方式来做到这一点,例如,利用许多模型内存之类的东西,以及当你处理诸如产品方面的……
任何这些模型时,就会知道如何进行足够的后期训练,而不会丢失它在预训练中所知道的东西,基本上不会以最简单的方式过度拟合,但我认为,这些技术、数据增强以及用于调整这种权衡的多次实验……
我认为这是一个挑战。在编排方面,这基本上是你正在启动一个作业。我是一个编排狂热者。那么你如何做到这一点呢?它像一个内部子工具吗?是的,所以我们为深度研究构建了这个异步平台,它基本上是……,在我们之前的许多交互中,都是同步的。是的,所有聊天内容都是同步的,对吧?没错。现在你可以离开聊天并返回。没错。并且关闭你的电脑等等。
现在它在 Android 上,并且正在 iOS 上推出。我看到你这么说。我告诉你我们有时会互换角色。好的,你在提醒他,对吧?是的,我们在……
所有 Android 手机上都完成了,然后 iOS 将在本周推出。但是,是的,很巧妙的是,你可以关闭你的电脑,在你的手机上收到通知,等等。所以这是一个你制作的某种 eSync 引擎。是的,是的。所以另一个是同步的概念,用户能够离开。
但如果你构建了 5、6 分钟的作业,它们也可能会失败,你也不想丢失你的进度等等。所以像保持状态、知道要重试什么以及继续旅程的概念。这有公共名称吗?不,我认为没有公共名称。数据科学家会说,这是一个 Spark 作业,或者,你知道,它像一个 Wraith,你知道,东西或者……
在旧的 Google 时代,可能就像 MapReduce 或者,你知道,无论什么,但这与那些事情相比,规模和工作性质都不同。所以我正在尝试为这个找到一个名字。
现在,这是我们的机会。是的,我们现在可以命名它。经典的事情是我过去在这个领域工作过。这就是我所问的。所以它是工作流程。所以有一些持久性的。这就像你还在 AWS 的时候一样。所以是 Apache Airflow、Temporal。顺便说一句,你们俩都在亚马逊工作过。是的,AWS Step Functions 将是其中之一,你可以定义一个执行图,但是 Step Functions 更静态,并且无法适应深度研究风格的后端。不过,很巧妙的是,我们构建这个是为了……
相当灵活,所以你可以想象一旦你开始做小时或数天工作,是的,你必须模拟代理想要做什么,确切地说,但也要确保它稳定,你知道,对于像数百个 LLM 调用,是的,这很无聊,但你知道,这是让它自主运行的东西,你知道,是的,所以它,是的,无论如何,我很兴奋,只是为了结束开放式内容,我认为我会说开放式内容很容易在营销方面击败你……
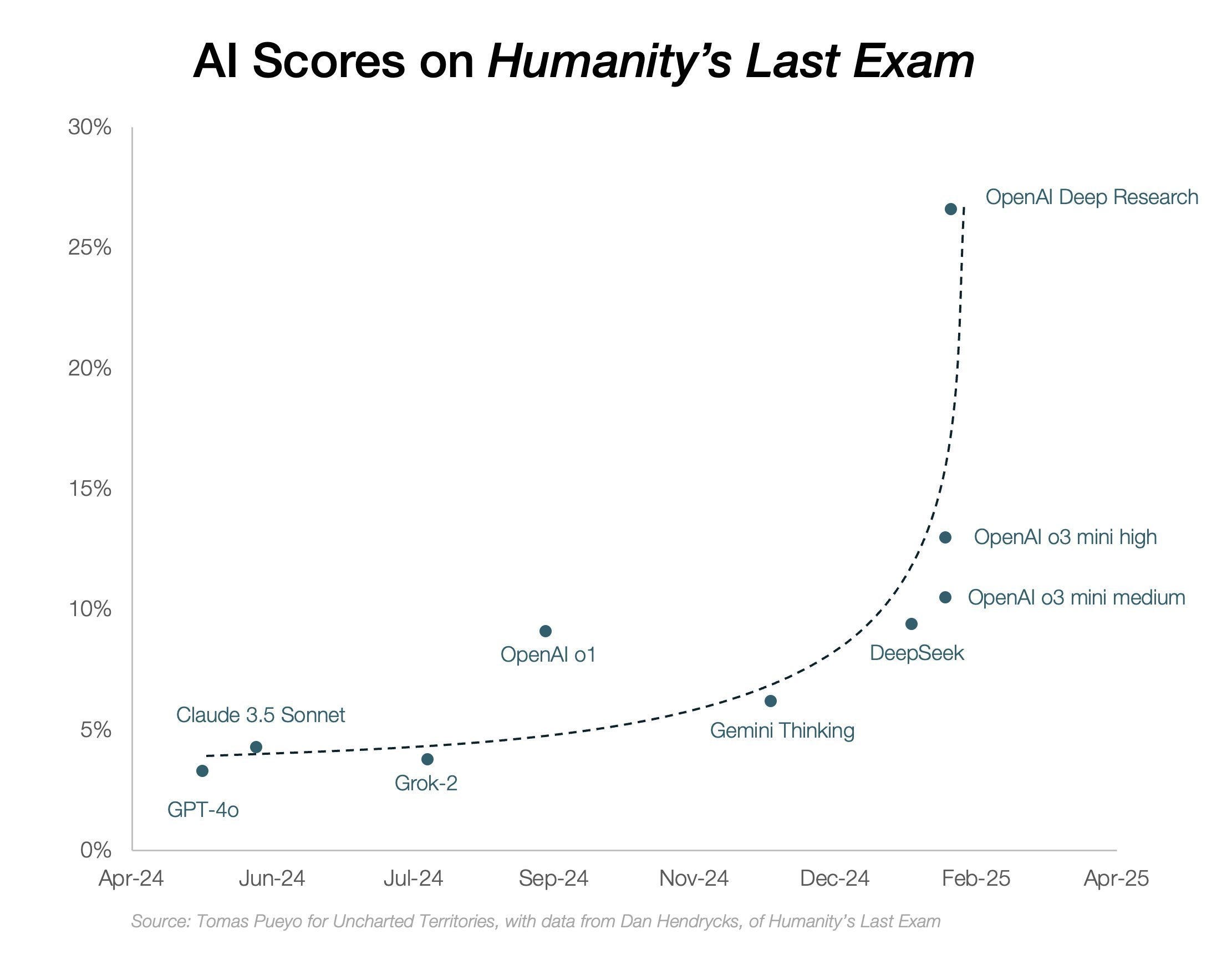
我认为这是因为你没有启动你的基准测试。我的问题是,你应该关心基准测试吗?你应该关心人类的最后一次考试吗?不是 MMLU,而是任何东西。他们就像,我认为基准测试很棒。我们想要避免的事情是科比·布莱恩进入联盟的那一天,他是总统的侄子,而且很奇怪,就像基准测试一样。他是科比的大粉丝。好的。就像这些没有人那样说话的奇怪的事情一样。所以,为什么我们要过度解决某种不一定会代表我们想要构建的产品体验的基准测试呢?尽管如此,基准测试对于行业来说仍然很棒,并且可以团结社区,帮助我们了解我们所处的位置。我不知道。你有任何吗?不,我认为你已经说到了点子上。我认为对我们来说,我们的主要目标是解决深度研究用户对用户用例的价值。我们看到的基准测试,至少……
它们并没有直接转化为产品。你肯定可以针对一些技术挑战进行基准测试,但它们并没有真正……就像,如果我在 HLE 上做得很好,这并不一定意味着我是一个很棒的深度研究人员。所以我们想避免陷入那个兔子洞。
但我们也觉得,是的,基准测试很棒,尤其是在整个 Gen I 空间中,模型每隔一天就会出现,每个人都声称自己是……所以这很棘手。另一个关于基准测试的重大挑战,尤其是在当今的模型方面,是输出空间熵。所有内容都像文本一样。因此,即使你得到了正确的答案,也有一个验证的概念。不同的实验室以不同的方式进行操作,但我们都比较数字。所以有很多……
你知道,艺术/弄清楚如何验证这个或如何在水平面上运行这个。但是,是的,所以我认为权衡肯定是对基准测试有价值的。但与此同时,我们也喜欢自私的 PM 视角。是的。
基准测试是激励研究人员的一个非常好的方法。就像让数字上升一样。没错。或者只是证明你是最好的。就像这是一种团结公司内部研究人员的好方法一样。就像我过去从事 MLPerf 基准测试工作一样,就像那样的,是的,你会把一群工程师放在一个房间里,几天之内,他们就会在我们的 TPU 堆栈上进行惊人的性能改进等等。对。所以就像拥有竞争性以及压力一样,真的会激励人们。
有一个基准测试是不可能进行基准测试的,但我只想让你知道,那就是深度研究,大多数人都在追逐发现新想法的这个想法。而现在的深度研究将以一种……你知道,更易于阅读的方式来总结网络,但它不会,你知道,从你搜索的内容中发现新事物需要什么?首先,我认为这种思维风格的模型在这里肯定会有所帮助,因为它们在描述方面明显更好……
自然地推理并能够得出这些二阶见解,这是非常前提的。如果你不能做到这一点,你就无法想象去做你提到的那样的事情。所以这是一个步骤。另一件事是,我认为这也取决于领域。所以有时你可以用模型来推导出新的假设,但是根据领域的不同,你可能无法验证该假设。所以编码数学,……
模型已经知道可以与之交互的工具相当不错,你可以运行验证器、测试假设等等。就像,即使你从纯粹的代理角度考虑,说,嘿,我在这个领域有这个假设,去弄清楚并告诉我,对吧?但是……
假设你是一个化学家,对吧?那么你会在那里做什么呢?我们还没有像合成环境这样的东西,模型能够通过在游乐场中玩耍来验证这些假设,并且拥有一个非常准确的验证器或奖励信号。计算机使用另一个,其中在开源研究中都有,等等,有一些不错的游乐场即将出现。所以,我认为如果你谈论的是真正能够想出,我个人的观点是模型不必……
必须进行我们现在在这些新模型中看到的二阶思考,而且还能够在一个可以验证并提供反馈的环境中进行游戏和测试,以便它可以继续交易。是的,所以基本上……
就像现在的代码沙箱一样,是的,是的,所以在这些情况下,我认为是的,更容易想象这个端到端,但并非所有领域都是如此,物理引擎,是的,是的,所以如果你更广泛地考虑代理,那么就会有很多事情需要考虑,你认为人们应该花时间研究的最有价值的部分是什么?就像我想到的事情,我看到很多早期公司都在关注的是记忆……
你知道,就像我们已经谈到了评估一样。我们稍微谈到了工具调用。这有点像身份验证部分。像,这个代理应该能够访问这个吗?如果是,你怎么验证呢?你希望更多人参与哪些工作,这对你会有所帮助?我可以从深度研究的角度来尝试一下这个,对吧?就像我认为我们真正感兴趣的一些事情,以及我们如何推动这个代理前进……
是像记忆一样的东西,比如个性化,对吧?就像如果我给你一份研究报告,如果你是高中生,我会给你报告的方式应该与如果你是博士或博士后,我会给你报告的方式完全不同,对吧?你可以提示它。你可以提示它。对。但第二件事是,它应该像理想地知道你所处的位置以及你所知道的一切,你知道,直到那时。对。并且进一步定制,对。对你的学习旅程有这种理解,并且……
我认为模态也将非常有趣。就像现在我们是文本输入,文本输出一样。我们应该在线。
多模态输入,对吧?但也多模态输出,对吧?就像我希望我的报告不仅仅是文本,而是图表、地图、图像,让它超级互动和多模态,对吧?并针对消费类型进行优化,对吧?所以我可能整理学术论文的方式应该与我尝试为孩子制作学习计划的方式完全不同,对吧?以及它的结构方式。理想情况下,就像你想用生成式 UI 之类的东西来真正定制报告一样。
我认为这些绝对是我个人在研究代理方面感兴趣的事情。我认为另一个非常重要的部分是,就像我们将达到开放网络的极限,并且你想要能够,就像人们关心的大多数事情都在他们自己的文档中一样。他们自己的语料库,他们个人真正关心的事情中的内容,对吧?就像,尤其当你更深入到特定行业时,对吧?
理想情况下,你希望人们能够用这些内容来补充他们的深度研究体验,以便进一步定制他们的答案。对此有两个答案。所以一个是,就我们的方法而言,至少对我来说,与其试图弄清楚像代理构建这样的核心任务,我觉得对我们来说还为时过早,试图将这些项目平台化或构建这些项目……
哦,有这五个水平部分,你可以即插即用并构建你自己的代理。我个人的观点是我们还没有到那里。为了构建一个超级引人入胜的代理,如果我要开始考虑一个新的想法,我会从这个想法开始,并尝试真正做好一件事情。是的,在某个时候,会有一个时间……
就像这些公共部分可以被提取出来,你知道,平台化一样。我知道跨公司和开源社区有很多工作正在进行,这些工作旨在提供这些工具来真正轻松地构建代理。我认为这些对于开始构建代理非常有用。但在某个时候,一旦这些工具使你能够构建基本层,我认为我个人会,你知道,尝试专注于真正策划一种体验,然后再广泛推广。
是的,我们有来自 Sierra 的 Bret Taylor,他大部分都是内部构建的。这对风投来说非常令人难过。他们想找到下一个伟大的框架和工具等等。但这个空间发展得如此之快。我描述的问题可能在六个月后就会过时。我不知道。我们将用另一个 LLM ops 平台来解决它。是的,是的。
好的,所以只是一个最后一点,只是插入你的演讲。人们会在你的演讲之前听到这个。你要谈些什么?你对纽约有什么期待?我很想从你们那里学习。你想让我们谈些什么?既然我们已经和你进行了这次谈话,你认为人们会发现什么最有趣?我认为有一点……
实施和一点愿景,大约 50-50。我认为你们俩都可以很好地扮演这些角色。每个人都知道你,你是一个非常精致的 Google 产品。我认为 Google 总是做得很好。但每个人都必须想要他们行业的深度研究。他投资了金融领域的深度研究,他们专注于他们的工作。并且将会有针对一切的深度研究,对吧?就像你在这里创建了一个 OpenAI 已经克隆的类别一样。
所以就像,好的,让我们谈谈,在这个品牌的代理中,哪些是难题,它可能是第一个真正具有产品市场契合度的代理。我会说比计算机使用代理更重要。这是人们像,是的,很容易支付每月 200 美元的东西,一旦你做得很好,可能就是 2000 美元。所以我想,好的,让我们谈谈如何从那些做到的人那里正确地做到这一点。然后这将走向何方?
所以,是的,这很简单。很乐意谈论这个。是的,谢谢。对我来说也是如此,你知道,我也很好奇看到你与其他演讲者互动,因为然后,你知道,还会有其他类型的代理问题。我对个性化非常感兴趣,对记忆非常感兴趣。我认为这些是相关的问题,规划、编排,所有这些事情。通常是安全,我们还没有谈到的事情。
有很多网络内容隐藏在墙后。我如何将我的凭据委托给你,以便你可以搜索我能够访问的内容?我认为这并不难。只是人们必须让他们的协议协同工作。这就是像这样的会议希望实现的目标。
是的,不,我非常兴奋。我认为对我们来说,就像我们经常在 Google 内部生活和呼吸一样,这是一个非常大的地方,但能够退一步,与在其他公司或完全不同的行业中处理这个问题的人见面,真的很好,对吧?就像不可避免地,至少在我们工作的地方,我们非常关注消费者领域。我明白了。对。了解 B2B 空间以及不同垂直领域中正在发生的事情也非常好。是的。
是的,他们想做的第一件事就是为我自己的文档进行深度研究,对吧?我的公司文档。所以很明显你会被问到这个问题。是的,我的意思是,还有更多内容需要讨论。我真的很期待你的演讲。是的,感谢你们的加入。是的,感谢你们的邀请。非常感谢你们,伙计们。