
“Compressed Computation is (probably) not Computation in Superposition” by Jai Bhagat, Sara Molas Medina, Giorgi Giglemiani, StefanHex
LessWrong (30+ Karma)
Shownotes Transcript
Audio note: this article contains 113 uses of latex notation, so the narration may be difficult to follow. There's a link to the original text in the episode description.
This research was completed during the Mentorship for Alignment Research Students (MARS 2.0) Supervised Program for Alignment Research (SPAR spring 2025) programs. The team was supervised by Stefan (Apollo Research). Jai and Sara were the primary contributors, Stefan contributed ideas, ran final experiments and helped writing the post. Giorgi contributed in the early phases of the project. All results can be replicated using this codebase. Summary
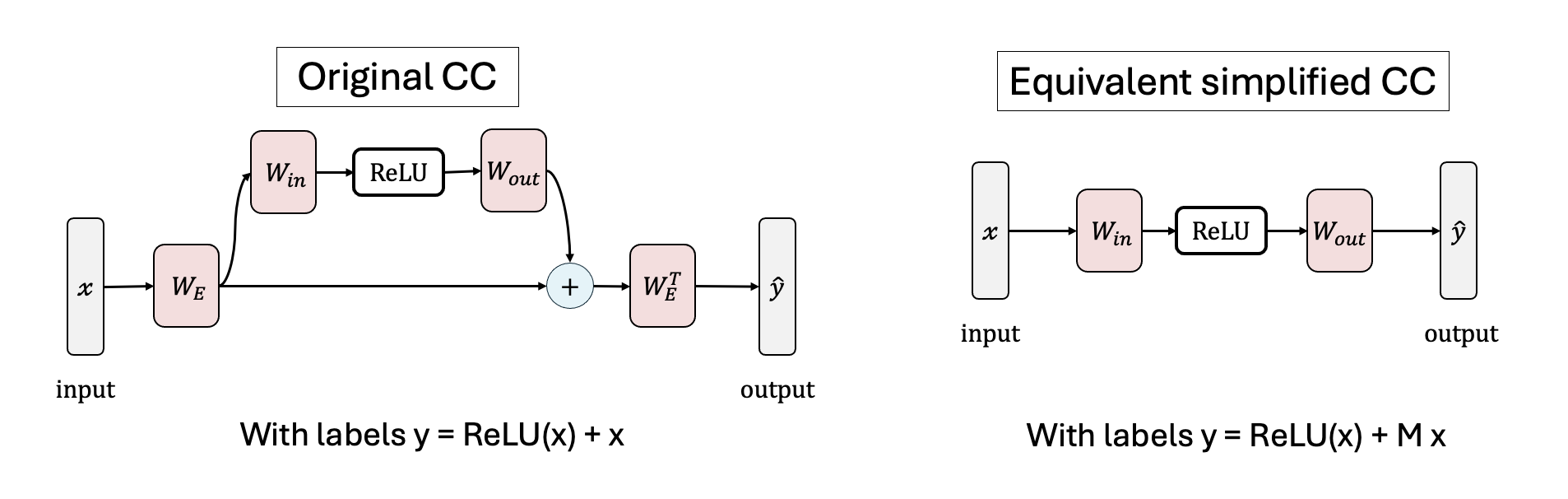
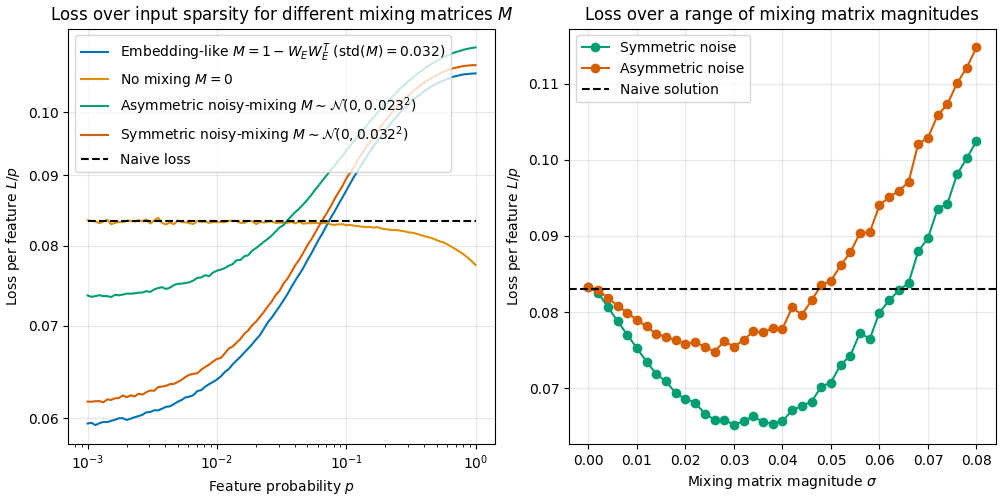
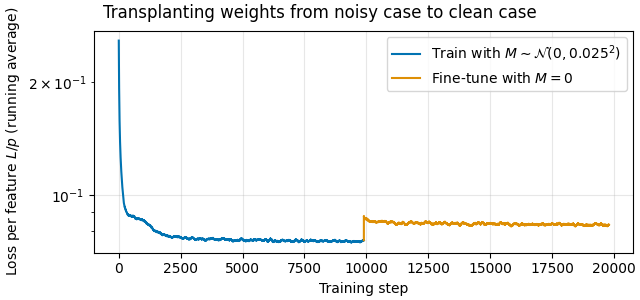
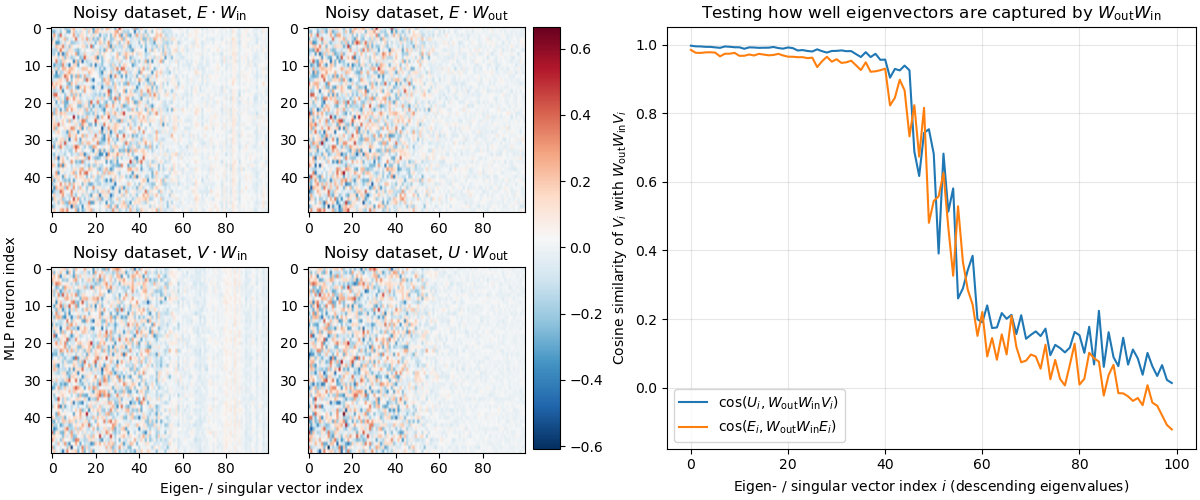
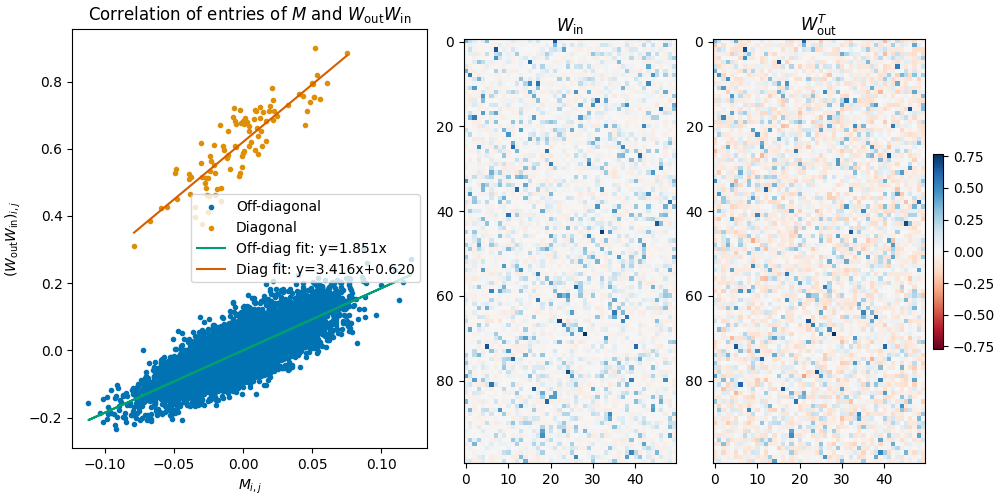
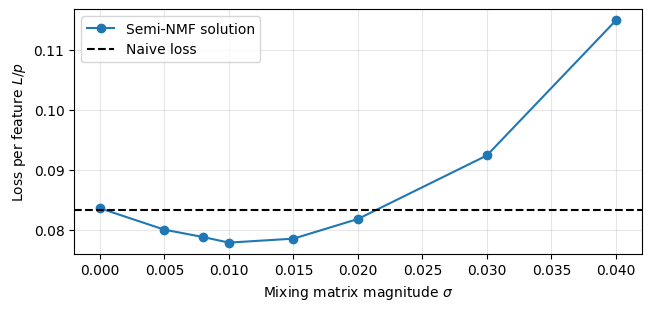
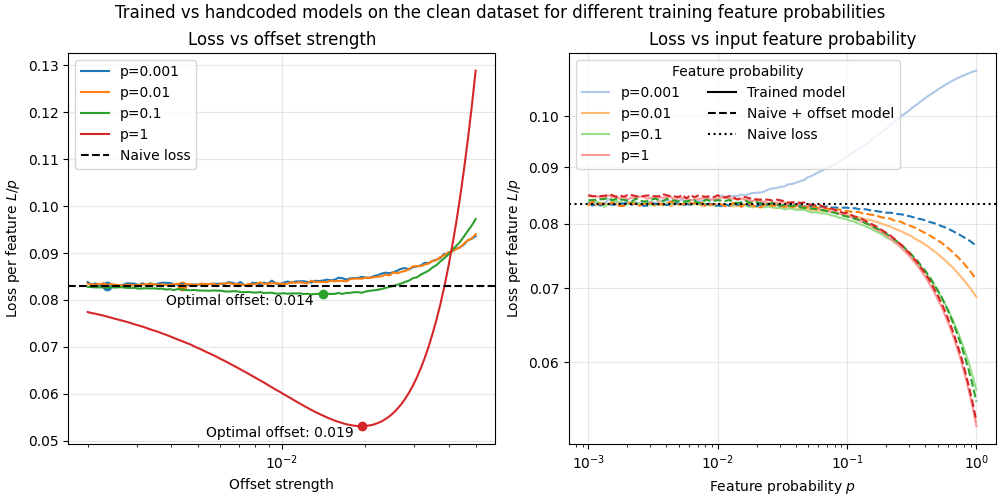
We investigate the toy model of Compressed Computation (CC), introduced by Braun et al. (2025), which is a model that seemingly computes more non-linear functions (100 target ReLU functions) than it has ReLU neurons (50). Our results cast doubt on whether the mechanism behind this toy model is indeed computing more functions [...]
Outline:
(00:59) Summary
(02:42) Introduction
(04:38) Methods
(06:34) Results
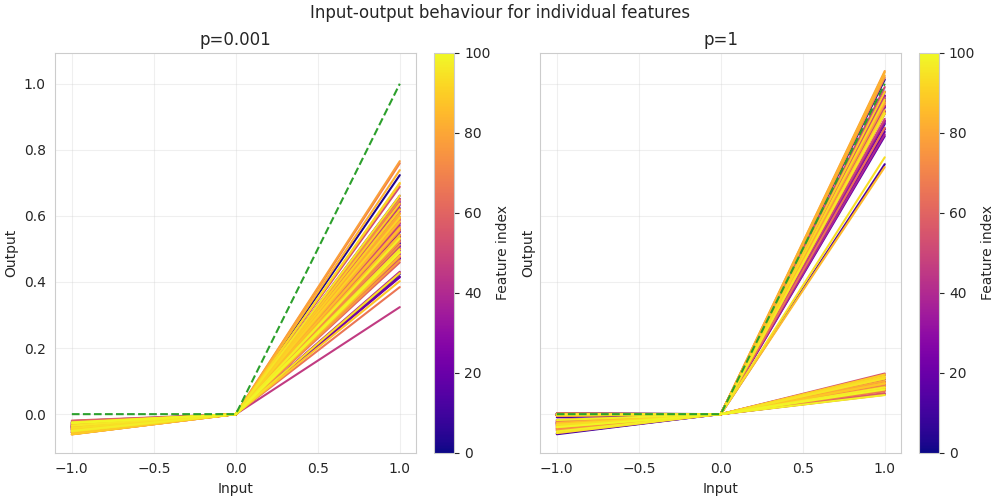
(06:37) Qualitatively different solutions in sparse vs. dense input regimes
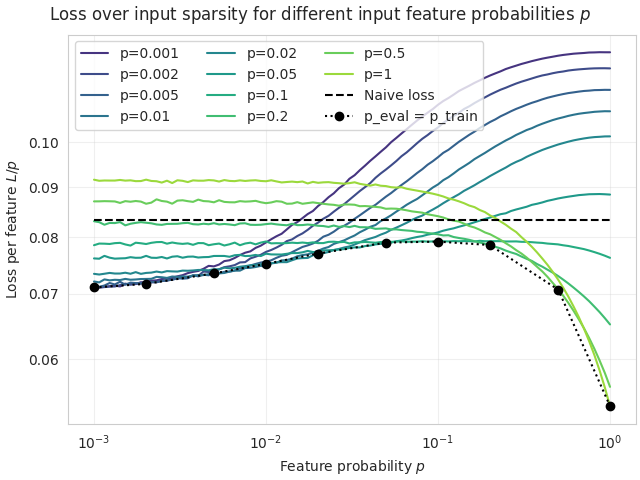
(09:49) Quantitative analysis of the Compressed Computation model
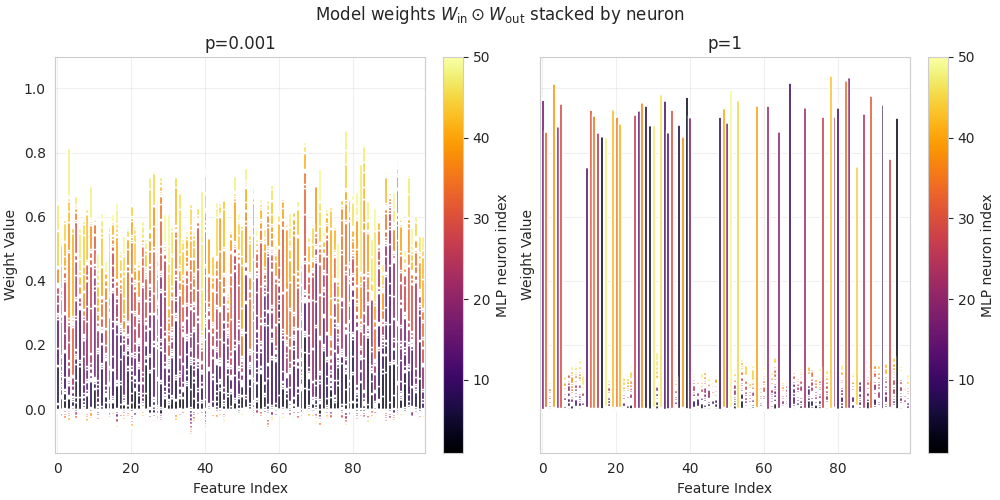
(13:09) Mechanism of the Compressed Computation model
(18:11) Mechanism of the dense solution
(20:55) Discussion
The original text contained 9 footnotes which were omitted from this narration.
First published: June 23rd, 2025
Narrated by TYPE III AUDIO).
Images from the article:
 )
) )
) )
) )
) )
) )
) )
) )
) )
) )
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts), or another podcast app.
)
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts), or another podcast app.