Beating Google at Search with Neural PageRank and $5M of H200s — with Will Bryk of Exa.ai

Latent Space: The AI Engineer Podcast — Practitioners talking LLMs, CodeGen, Agents, Multimodality, AI UX, GPU Infra and all things Software 3.0
Deep Dive
Shownotes Transcript
Hey everyone, welcome to the Lid in Space podcast. This is Alessio, partner and CTO in Residence and Decibel Partners, and I'm joined by my co-host Swix, founder of SmallAI. Hey, and today we're in the studio with my good friend and former landlord, Will Brick. Yeah, roommate. How you doing? Will, you're now CEO co-founder of ExaAI, used to be Metaphor Systems. What's your background and your story?
Yeah, sure. So yeah, I'm CEO of Exa. I've been doing it for three years. I guess I've always been interested in search, whether I knew it or not. Like since I was a kid, I've always been interested in like high quality information. And like, you know, even in high school, wanted to improve the way we get information from news. And then in college, built a mini search engine. And then with Exa, like, you know, it's kind of like fulfilling the dream of
actually being able to solve all the information needs I wanted as a kid. Yeah, I guess I would say my entire life has kind of been rotating around this problem, which is pretty cool. Yeah. What do you enter YC with? We entered YC with We Are Better Than Google.
at Google 2.0. What makes you say that? That's so audacious to come out of the box with. Yeah. Okay. So you have to remember the time. This was summer 2021. And GBD3 had come out. Here was this magical thing that you could talk to, you could enter a whole paragraph, and it understands what you mean, understands the subtlety of your language. And then there was Google, which felt like it hadn't changed in a decade, because it really hadn't. And you would give it a simple query, like, I don't know,
shirts without stripes, and it would give you a bunch of results for the shirts with stripes. And so like Google could barely understand you, but GB3 could. And the theory was, what if you could make a search engine that actually understood you? What if you could apply the insights from LLMs to a search engine? And it's really been the same idea ever since. And we're actually a lot closer now to doing that.
Did you have any trouble making people believe? Obviously, there's a Sam Allman, YC overlap. Was YC pretty AI forward, even 2021? It's nothing like it is today. But there were a few AI companies, but we were definitely like bold. And I think people, VCs generally like boldness. And we definitely had some AI background and we had a working demo. So there was evidence that we could build
build something that was going to work. But yeah, I think like the fundamentals were there. I think people at the time were talking about how, you know, Google was failing in a lot of ways. And so there was a bit of conversation about it. But I was not a big, big thing at the time. Yeah. Before we jump into any fun background stories, I know you intern at SpaceX, any Elon stories. I know you were at Zoox as well, you know, kind of like robotics at Harvard. Any stuff that you saw early that you thought was going to get solved and maybe it's not solved today?
Oh yeah, I mean lots of things like that. Like I never really learned how to drive because I believed Elon that self-driving cars would happen. It did happen and I'd take them every night to get home but it took like 10 more years than I thought. Do you still not know how to drive? I know how to drive now. I learned it like two years ago. That would have been great to like just, you know. I was obsessed with Elon, yeah. I mean I worked at SpaceX because I really just wanted to work at one of his companies and I remember they had a rule like interns cannot touch Elon.
And that rule actually influenced my actions. Is it? Like physically? Or like talk? Physically, physically. Okay, interesting. He's changed a lot, but I mean, his companies are amazing. What if you beat him at Diablo 2, Diablo 4, you know? Oh, maybe. Yeah.
Yeah, I want to jump in, because I know there's a lot of backstory. It used to be called Metaphor System. And you've always been kind of like a prominent company, maybe at least RAI circles in SF. Yeah, I'm actually curious how Metaphor got its initial aura. You launched with, like, very little. Yeah.
We watched very little. There was this big splash image of this aurora or something, right? And then I was like, okay, what this thing, the vibes are good, but I don't know what it is. And I think it was much more sort of maybe consumer facing than what you are today. Would you say that's true?
No, it's always been about building a better search algorithm. The vision has always been perfect search. And if you do that, we will figure out the downstream use cases later. It started on this fundamental belief that you could have perfect search over the web. And we could talk about what that means. And the initial thing we released was really just our first search engine, trying to get it out there. Kind of like when OpenAI released ChatsBt, they didn't
I don't know how much of a game plan they had. They kind of just wanted to get something out there. A spooky research preview. Yeah, exactly. And it kind of morphed from a research company to a product company at that point. And I think similarly for us, like we were research, we started as a research endeavor with clear eyes that like if we succeed, it will be a massive business to make out of it. And that's kind of basically what happened. I think there are actually a lot of parallels between EXA and OpenAI. I often say we're the OpenAI of search because we're a research company
We're a research startup that does fundamental research into making AGI for search, in a way. And then we have all these business products that come out of that.
Interesting. I want to ask a little bit more about Metaforesight and then we can go full EXA. When I first met you, which was really funny because literally I stayed in your house in a very historic Hayes Valley place. You said you were building sort of like link prediction foundation model. And I think there's still a lot of foundation model work within EXA today. But what does that even mean? I cannot be the only person confused by that.
Because there's a limited vocabulary of tokens. You're telling me the tokens are the links? It's not clear. Yeah, what we meant by link prediction is that you are literally predicting, given some text, you're predicting the links that follow. Yes. That refers to, it's how we describe the training procedure, which is that we find links on the web. We take the text,
surrounding the link, and then we predict which link follows. So you're like, you know, similar to Transformers where you're trying to predict the next token. Here, you're trying to predict the next link. Link.
And so you kind of hide the link from the transformer. So if someone writes, imagine some article where someone says, hey, check out this really cool aerospace startup, and they say SpaceX.com afterwards, we hide the SpaceX.com and ask the model what link came next. And by doing that many, many times, billions of times, you could actually build a search engine out of that because then...
At query time, at search time, you type in a query that's like really cool aerospace startup and the model will then try to predict what are the most likely links. So there's a lot of analogs to transformers, but like to actually make this work, it does require like a different architecture. Yeah. But it's transformer inspired. Yeah.
What's the design decision between doing that versus extracting the link and the description and then embedding the description and then using... Typical, right? Yeah. What do you need to predict the URL versus just describing? Because you're kind of doing a similar thing in a way, right? It's kind of like, based on this description, what's the closest link for it?
So one thing is I'm predicting the link. The other approach is like I extract the link in the description and then based on the query, I search the closest description to it. Yeah, by the way, that is the link refers here to a document. It's not... I think one confusing thing is you're not actually...
predicting the url itself yeah that would require like the the system to have memorized urls you're actually like getting the actual document a more accurate name could be document prediction i see this was the initial like base model that x was trained on but we've moved beyond that similar to like how you know uh to train a really good like language model you might start with this like self-supervised objective of predicting the next token and then just from random stuff on the web but then you
You want to add a bunch of synthetic data and supervise fine tuning, stuff like that, to make it really controllable and robust. FRANCESC CAMPOY: Yeah. Yeah, we just had flow from Lindy. And there, Lindy started to like hallucinate recrolling YouTube links instead of like a support guide. So-- MARK MANDEL: Oh, interesting. FRANCESC CAMPOY: Yeah. MARK MANDEL: So round about January, you announced your Series A and renamed to Exa. I didn't like the name at the initial-- but it's grown on me. I like the metaphor. But apparently, people can spell metaphor.
What would you say are the major components of Exa today? I feel like it used to be very model heavy. Then at the AI Engineer Conference, Shreyas gave a really good talk on the vector database that you guys have.
What are the other major moving parts of Excel? Okay, so Excel overall is a search engine, and we're trying to make it like a perfect search engine. And to do that, you have to build lots of... And we're doing it from scratch, right? So to do that, you have to build lots of different subsystems. You have to crawl a bunch of the web. First of all, you have to find the URLs to crawl. It's connected to the crawler, but yeah, you find URLs, you crawl those URLs, then you have to process them with some...
It could be an embedding model. It could be something more complex. But you need to take... Or in the past, it was like a keyword inverted index. You would process all these documents you gather into some processed index, and then you have to serve that at high throughput at low latency. And that's like the vector database. And so it's like the crawling system...
the AI processing system, and then the serving system. Those are all teams of hundreds, maybe thousands of people at Google. But for us, it's one or two people each, typically. Can you explain the meaning of EXA? Just the story, 10 to the 16th. I think it's 10 to the 18th. Yeah, sure. EXA means 10 to the 18th, which is in stark contrast to Google, which is 10 to the 100th. We actually have these awesome shirts that are like,
10th to the 18th is greater than 10th to the 100th. Yeah, it's great. And it's great because it's provocative. It's like every engineer in Silicon Valley is like, what? No, it's not true. Like, yeah. And then you ask them, okay, what does it actually mean? And like the creative ones will recognize it. But yeah, I mean, 10th to the 18th is better than 10th to the 100th when it comes to search because with search, you want like the actual list of things that match what you're asking for. You don't want like the whole web. You want to basically with search filter everything
everything that humanity has ever created to exactly what you want. And so the idea is like smaller is better there. You want like the best 10th to the 18th and not the 10th to the 100th. Like one way to say this is like, you know how Google often says at the top, like, you know, 30 million results found. And it's like crazy because you're looking for like different.
the first two pages. Startups in San Francisco that work on hardware or something and like, they're not 30 million results like that. What you want is like 325 results found and those are all the results. That's what you really want with search and that's our vision. It's like, it just gives you perfectly what you asked for. We're recording this ahead of your launch. We haven't released, we haven't figured out the, the,
the name of the launch yet, but what is the product that you're launching, I guess, now that we're coinciding this podcast with? Yeah, so we've basically developed the next version of EXA, which is the ability to get a near-perfect list of results of whatever you want. And what that means is you can make a complex query now to EXA, for example, startups working on hardware in SF,
and then just get a huge list of all the things that match. And our goal is if there are 325 startups that match that, we find you all of them. And this is just a new experience that's never existed before. I don't know how you would go about that right now with current tools. And you can apply this same type of technology to anything. Let's say you want to find all the blog posts that talk about Swix's podcast.
that have come out in the past year. That is 30 million results. Yeah, right.
I'm sure that would be extremely useful to you guys. And I don't really know how you would get that full comprehensive list. I just like, how do you... Well, there's so many questions with regards to how do you know it's complete, right? Because you're saying there's only 30 million, 325, whatever. And then how do you do the semantic understanding that it might take, right? So working in hardware, I might not use the words hardware. I might use the words robotics. I might use the words wearables. I might use whatever. So yeah, just...
I was more... Yeah, yeah, sure. So one aspect of this is it's a little subjective. So certainly providing... At some point, we'll provide parameters to the user to some sort of threshold to gauge, like, okay, this is a cutoff. This is actually not what I mean. Because sometimes it's subjective and there needs to be a feedback loop. It might give you a few examples and you say... Is this what you want? Yeah, exactly. And so you're kind of creating a classifier on the fly.
But that's ultimately how you solve the problem. So there's a subjectivity problem and then there's a comprehensiveness problem. Those are two different problems. So to solve the comprehensiveness problem, what you basically have to do is you have to put more compute into the query, into the search, until you get the full comprehensiveness. And...
There's an interesting point here, which is that not all queries are made equal. Some queries, just like this blog post one, might require scanning, scavenging throughout the whole web in a way that just simply requires more compute.
you know at some point there's some amount of compute where you will just be comprehensive you could imagine for example running gpd4 over the entire web and saying like is this a blog post about swiss podcast podcast like is this blog post about swiss podcast and then that would work right it would take you know a year maybe cost like a million dollars but or many more but um it would work uh the point is that like given sufficient compute you can solve the query and so it's really a question of like how comprehensive do you want it given your compute budget
I think it's very similar to O1, by the way. And one way of thinking about what we built is like O1 for search. Because O1 is all about like, you know, some questions require more compute than others. And we'll put as much compute into the question as we need to solve it. So similarly with our search, we will put as much compute into the query in order to get comprehensiveness. Yeah. Does that mean you have like some kind of compute budget that I can specify? Yes. Okay. And like what are the upper and lower bounds? Yeah.
Yeah, this is something we're still figuring out. I think everyone has a new paradigm of variable compute products. How do you specify the amount of compute? What happens when you run out? Can you keep going with it? Do you just put in more credits to get more? This can get complex at the really large compute queries. One thing we do is we give you a preview of what you're going to get, and then you could then spin up a much larger job to get more.
way more results. But yes, there is some compute limit, at least right now. People think of searches as like, oh, it takes 500 milliseconds because we've been conditioned to have a search that takes 500 milliseconds by search engines like Google, right? No matter how complex your query to Google, it will take roughly 400 milliseconds. But what if searches can take a minute or 10 minutes or a whole day? What can you then do? And you can do very powerful things. You can imagine writing a search
going to get a cup of coffee, coming back, and you have a perfect list. Like that's okay for a lot of use cases. The use case closest to me is venture capital, right? So, no, I mean, eight years ago, I built one of the first like data-driven sourcing platforms. So we would look at GitHub, Twitter, Product Hunt, all these things, look at interesting things, evaluate them. If you think about some jobs that people have, it's like literally just make a list. If you're like an analyst at a venture firm, your job is to make a list of interesting companies and then you reach out to them.
How do you think about being infrastructure versus like a product? You could say, hey, this is like a product to find companies. This is a product to find things versus like offering more as a blank canvas that people can build on top of. Oh, right, right. We are a search infrastructure company, so we want people to build products
on top of us, build amazing products on top of us. But with this one, we tried to build something that makes it really easy for users to just log in, put some credits in and just get like amazing results right away and not have to wait to build some API integration. So we're kind of doing both.
We want people to integrate this into all their applications. At the same time, we want to just make it really easy to use. Very similar, again, to OpenAI. Like, they'll have, they have an API, but they also have like a Chachapiti interface. So you could, it's really easy to use, but you could also build it in your applications. Yeah. I'm still trying to wrap up
wrap my head around a lot of the implications. So, so many businesses run on like information arbitrage, you know, like I know this thing that you don't, especially in investment and financial services. So yeah, now all of a sudden you have these tools for like, oh, actually everybody can get the same information at the same time, the same quality level as an API call, you know, it just kind of changes everything.
A lot of things. Yeah, I think what we're grappling with here, what you're just thinking about is like, what is the world like if knowledge is kind of solved? If like any knowledge request you want
is just like right there on your computer it's kind of different from when intelligence is solved there's like a good i've written before about like a difference yeah like i think that the distinction between intelligence and knowledge is actually a pretty good one they're definitely connected and related in all sorts of ways but there is a distinction you could have a world and we are going to have this world where you have like gb5 level systems and beyond that could like answer any complex request um unless it requires some like if you say like
you know, give me a list of all the PhDs in New York City who, I don't know, have thought about search before. And even though this super intelligence is going to be like,
I can't find it on Google, right? Which is kind of crazy. Like we're literally going to have like super intelligences that are using Google. And so if Google can't find the information, there's nothing they could do. They can't find it. But if you also have a super knowledge system where it's like, you know, I'm calling this term super knowledge where you just get whatever knowledge you want, then you can pair it with a super intelligence system and then the super intelligence will never be blocked by lack of knowledge. Yeah, you told me this when we had lunch.
I forget how it came up, but we were talking about AGI and whatnot, and you were like, even AGI is going to need search. Yeah, right. Yeah. So we're actually referencing a blog post that you wrote, Superintelligence and Superknowledge. So I refer people to that. And this is actually a discussion we've had on the podcast a couple of times. There's so much of model weights that are just memorizing facts.
Some of those might be outdated, some of them are incomplete or not. Yeah, so you just need search and tool use. So I do wonder, is there a maximum language model size that will be the intelligence layer, and then the rest is just search? Maybe we should just always use search, and then the sort of workhorse model is just like 1B or 3B parameter model that just drives everything. Yeah.
Yes, I believe this is a much more optimal system to have a smaller LLM that's really just like an intelligence module and it makes a call to a search tool. That's way more efficient because if, okay, I mean, the opposite of that would be like the LLM is so big that it can memorize the whole web. That would be like
way, you know, it's not practical at all. It's not possible to train that, at least right now. And Karpathy's actually written about this, how like he could see models moving more and more towards like intelligence modules using various tools. Yeah, so for listeners, that's the, that was him on the No Priorities podcast. And for us, we talked about this on the Xinyu and Harrison Chase podcasts. I'm doing search in my head. That's pretty cool. I told you, 30 million results. I forgot about our Neuralink integration. Self-hosted exit.
Yeah, no, I do see that that is a much more efficient world. I mean, you could also have GB4 level systems calling search, but it's just because of the cost of inference, it's just better to have a very efficient search tool and a very efficient LLM and they're built for different things. Yeah. I'm just kind of curious, like it is still something so audacious that I don't want to
which is you're building a search engine. Where do you start? How do you... Are there any reference papers or implementations that would really influence your thinking? Anything like that? Because I don't even know where to start apart from just crawl a bunch of shit. But there's got to be more insight than that. I mean, yeah, there's more insight, but...
I'm always surprised by, like, if you have a group of people who are really focused on solving a problem with the tools today. Like, there's so many in software. Like, there are all sorts of creative solutions that just haven't been thought of before. Particularly in the information retrieval field. Yeah. I think a lot of the techniques are just very old, frankly. Like, I know how Google and Bing work. And...
They're just not using new methods. There are all sorts of reasons for that. Like one, like Google has to be comprehensive over the web. So they're, and they have to return in 400 milliseconds. And those two things combined means they are kind of limited and it can't cost too much. They're kind of limited in what kinds of algorithms they could even deploy at scale. So they end up using like
a limited keyword-based algorithm. Also, like, Google was built in a time where, like, in, you know, 1998, where we didn't have LLMs, we didn't have embeddings. And so they never thought to build those things. And so now they have this, like, gigantic system that is built on old technology. And so a lot of the information retrieval,
we found just like thinks in terms of that framework. Whereas we came in as like newcomers just thinking like, okay, here's GB3. It's magical. Obviously, we're going to build search that is using that technology. And we never even thought about using keywords. Really ever. Like,
We were neural all the way. We're building an end to end neural search engine. And just that whole framing just makes us ask different questions, like pursue different lines of work. And there's just a lot of low hanging fruit because no one else is thinking about it. We're just on the frontier of neural search. We just are for, for web scale. Um, because there's just not a lot of people thinking that way about it. Yeah. Maybe let's spell this out since we're already on this topic.
Elephants in the room are Proplexity and SearchGPT. I think it's no longer called SearchGPT. I think they call it ChatGPT search. How would you contrast your approaches to them based on what we know of how they work? And yeah, just anything in that area. Yeah, so these systems, there are a few of them now. They basically rely on traditional search engines like Google or Bing. And then they combine them with LLMs at the end to output some paragraph answering your question. So they...
like search gbt perplexity i think they have their own crawlers no or so there's this important distinction like having your own search system and like having your own cache of the web okay like for example so you could create you could crawl a bunch of the web imagine you crawl 100 billion urls and then you create a key value store of like mapping from url to the document that is technically called an index but it's not a search algorithm so then to actually like
When you make a query to search dbt, for example, what is it actually doing? Let's say it's using the Bing API, getting a list of results, and then it has this cache of all the contents of those results and then can bring in the cache, the index cache. But it's not like they've built a search engine from scratch over hundreds of billions of pages. Is that distinction clear? It's like...
You could have a mapping from URL to documents, but then rely on traditional search engines to actually get the list of results. Because it's a very hard problem to take. It's not hard to use DynamoDB and map URLs to documents. It's a very hard problem to take 100 billion or more documents and give it a query, instantly get the list of results that match. That's a much harder problem that very few entities on the planet have solved.
done. Like there's Google, there's Bing, you know, there's Yandex, but you know, there are not that many companies that are crazy enough to actually build their search engine from scratch when you could just use traditional search APIs.
So Google had PageRank as the big thing. Is there an LLM equivalent or any stuff that you're working on that you want to highlight? The link prediction objective can be seen as a neural PageRank because what you're doing is you're predicting the links people share. And so if everyone is sharing some Paul Graham essay about fundraising, then our model is more likely to predict it. So inherent in our training objective is this...
a sense of like high canonicity and like high quality, but it's more powerful than PageRank. It's strictly more powerful because people might refer to that Paul Graham fundraising essay and like,
a thousand different ways. And so our model learns all the different ways that someone refers that Paul Graham essay while also learning how important that Paul Graham essay is. So it's like, it's like page rank on steroids kind of thing. Yeah. I think to me, that's the most interesting thing about search today, like with Google and whatnot. It's like, it's mostly like domain authority. So like if you get backlink, like if you search any AI term, you get this like SEO slop,
websites with like a bunch of things in them. So this is interesting. But then how do you think about more timeless maybe content? So if you think about, you know, maybe the founder mode essay, right? It gets shared by like a lot of people, but then you might have a lot of other essays that are also good, but they just don't really get a lot of traction, even though maybe the people that share them are high quality. How do you kind of solve that thing when you don't have...
the people authority, so to speak, of who's sharing whether or not they're worth kind of like bumping up. Yeah, I mean, you do have a lot of control over the training data. So you could like make sure that the training data contains like high quality sources so that, okay, like if you, if your training data, I mean, it's very similar to like language model training. Like if you train on like a bunch of crap, your prediction will be crap. Our model will match the training distribution it's trained on. And so we could like, there are lots of ways to tweak the training data to,
refer to high quality content that we want. Yeah, I would say also this like
this slop that is returned by traditional search engines like Google and Bing, you have the slop is then transferred into these LLMs in a search GBT or other systems like that. If slop comes in, slop will go out. And so, yeah, that's another answer to how we're different is we're not like traditional search engines. We want to give the highest quality results and have full control over whatever you want. If you don't want slop, you get that. And then...
If you put an LLM on top of that, which our customers do, then you just get higher quality results or high quality output. And I use ExaSearch very often and it's very good. You said BrightWave uses it too? Yeah, yeah, yeah, yeah. Like the slop is everywhere, especially when it comes to AI, when it comes to investment, when it comes to all of these things where like it's valuable to be at the top. And this problem is only going to get worse because... Yeah, no, totally. What else is in the toolkit? So you have...
Search API, you have ExaSearch, kind of like the web version. Now you have the list builder. I think you also have web scraping. Maybe just...
touch on that? Like, I guess maybe people, they want to search and then they want to scrape, right? So is that kind of the use case that people have? Yeah. A lot of our customers, they don't just want, because they're building AI applications on top of Exa, they don't just want a list of URLs. They actually want like the full content, like cleans, parsed, markdown, maybe chunked, whatever they want, we'll give it to them. And so that's been like huge for customers, just like getting the URLs and instantly getting the content for each URL is like
And you can do this for 10 or 100 or 1,000 URLs, whatever you want. That's very powerful. Yeah, I think this is the first thing I asked you for when I tried using Exa. Funny story is when I built the first version of Exa, we just happened to store the content, the first 1,024 tokens, because I just kind of kept it because I thought of, I don't know why, really for debugging purposes. And so then when people started asking for content, it was actually pretty easy to serve it. Yeah.
And then we did that, like, Exo took off. So the music's content was so useful. So that was kind of cool. It is. I would say there are other players, like Gina, I think, is in this space. Firecrawl is in this space. There's a bunch of scraper companies. And obviously, scraper is just one part of your stack, but you might as well offer it since you already do it. Yeah, it makes sense. It's just easy to have an all-in-one solution and, like,
we are building the best scraper in the world. So scraping is a hard problem and it's easy to get a good scraper. It's very hard to get a great scraper and it's super hard to get a perfect scraper. So like
And scraping really matters to people. Do you have a perfect scraper? Not yet. The web is increasingly closing to the bots and the scrapers. Twitter, Reddit, Quora, Stack Overflow. I don't know what else. How are you dealing with that? How are you navigating those things? Like, you know, opening eyes, like just paying them money. Yeah.
Yeah, no, I mean, I think it definitely makes it harder for search engines. One response is just that there's so much value in the long tail of sites that are open. And just like even just searching over those well gets you most of the value. But I mean, there is definitely a lot of content that is increasingly not unavailable. And so you could get through that through data partnerships. The bigger we get as a company, the more the easier it is to just like make partnerships. But I mean, I do see the world as like the future where the data is
the data producers, the content creators will make partnerships with the entities that find that data. Any other fun use case that maybe people are not thinking about? Yeah. Oh, I mean, there are so many. Your customers. Yeah, yeah. What are people doing on AXA? Well, I think dating is a really interesting topic
application of search that is completely underserved because there's a lot of profiles on the web and a lot of people who want to find love. And that I'll use it. Give me like, you know, age boundaries, you know, education level location. Yeah. I mean, you want to, what do you want to do with dating? You want to find like a partner who matches this education level, who like, you know, maybe has written about these types of topics before. Like if you get a list of all the people like that, like I think,
you will unblock a lot of people. I mean, I think this is a very Silicon Valley view of dating for sure. And I'm well aware of that. But it's just an interesting application of like, you know, I would love to meet like an intellectual partner who like shares a lot of ideas. And if you could do that through better search. Yeah. But what is with Jeff? Jeff already set me up with a few people. So like Jeff, I think is my personal ex-wife. Yeah.
My mom's actually a matchmaker and has gotten a lot of people married. No kidding. Yeah, yeah, yeah. Search is built into the book. It's in your genes. Yeah, yeah, yeah. Other than dating, I know you're having quite some success in colleges. I would just love to map out some more use cases so that our listeners can just use those examples to think about use cases for EXA, right? Because it's such a general technology that it's hard to really pin down what should I use it for and what kind of products can I build with it.
Yeah, sure. So, I mean, there are so many applications of Exa and we have, you know, many, many companies using us for a very diverse range of use cases. But I'll just highlight some interesting ones. Like one customer, a big customer is using us to basically build like a writing assistant for students who want to write research papers. And basically like Exa will search for like a list of research papers related to what the student is writing. And then this product has like an LLM that like summarizes the
the papers to basically it's like an X word prediction, but in, you know, prompted by like, you know, 20 research papers that X has returned. It's like literally just doing their homework for them. Yeah. Yeah. But the key point is like, it's, it's, you know, it's, it's, you know, research is a really hard thing to do and you need like high quality content as input. Oh, so we've had illicit on the podcast. I think it's pretty similar. They do focus on,
pretty much on just research papers and that research use case. Basically, I think dating research, I just wanted to spell out more things. Like just the big verticals. Yeah, yeah. No, I mean, there are so many use cases. Finance, we talked about. Yeah, I mean, one big vertical is just finding a list of companies. So it's useful for VCs, like you said, who want to find like a list of
competitors to a specific company they're investigating or just a list of companies in some field. There was one VC that told me that him and his team were using Exa for eight hours straight for many days on end, just doing lots of different queries of different types. Like, oh, all the companies in AI for law or all the companies for AI for construction and just getting lists of things because you just can't find this information with traditional search engines.
And then finding companies is also useful for selling. If we want to find a list of writing assistants to sell to, then we just use Exa ourselves to find. That's actually how we found a lot of our customers. Ooh, you can find your own customers using Exa. Oh, my God. In the spirit of using Exa to bolster Exa, recruiting is really helpful. It's a really great use case of Exa because we can just get a list of people who thought about search and just get a long list.
and then reach out to those people. - When you say thought about, are you thinking LinkedIn, Twitter, or are you thinking just blogs? - Or they've written, I mean it's pretty general. So in that case, ideally Exo would return the really blogs written by people who have just-- - So if I don't blog, I don't show up to Exo, right? Like I have to blog.
It's like an incentive for people to blog. Well, if you've written about search on Twitter and we do index a bunch of tweets and then we should be able to service that. I mean, this is something I tell people, like, you have to make yourself discoverable to the web. It's called learning in public, but
Like, it's even more imperative now. Yes. Because otherwise you don't exist at all. Yeah. No, this is a huge thing, which is like, search engines completely influence... They have downstream effects. They influence the internet itself. They influence what people choose to create. And so...
Google, because they're a keyword-based search engine, people kind of like... Keyword stuff. Yeah, they're incentivized to create things that just match a lot of keywords, which is not very high quality. Whereas Exa is a search algorithm that optimizes for high quality and actually matching what you mean. And so people are incentivized to create content that is high quality, that like...
They create content that they know will be found by the right person. So if I am a search researcher and I want to be found by Exa, I should blog about search and all the things I'm building because now we have a search engine like Exa that's powerful enough to find them.
And so the search engine will influence the downstream internet in all sorts of amazing ways. Whatever the search engine optimizes for is what the internet looks like. Are you familiar with the term McLuhanism? No, what's that? It's this concept that first we shape tools and then the tools shape us. So there's this reflexive connection between the things we search for and the things that get searched for.
Yes. So like once you change the tool that searches, the things that get searched also change. Yes. I mean, there was a clear example of that. 30 years of Google. Yeah, exactly. Google has basically trained us to think of search. Google has, Google is search like in people's heads, right? One hard part about Exa is like, uh,
ripping people away from that notion of search and expanding their sense of what search could be. Because when people think search, they think a few keywords, or at least they used to. They think of a few keywords and that's it. They don't think to make these really complex paragraph long requests for information and get a perfect list. Chachupi Tea was an interesting thing that expanded people's understanding of search because you start using Chachupi Tea for a few hours and you go back to Google and you paste in your code
and Google just doesn't work. And you're like, oh wait, Google doesn't work that way. So like Chachapiti expanded our understanding of what search can be. And I think Exa is part of that. We want to expand people's notion like, hey, you could actually get whatever you want. Yeah. How do you think about terms...
How would I say it? So I search on Excel right now, people writing about learning in public. I was like, is it going to come out with specs? You're not because it's so about... Because it thinks about learning in public, like public schools and focuses more on that. It's like how...
When there are these highly overlapping things, this is a good result based on the query. But how do I get to SWIX? So if you're in these subcultures, I don't think this would work in Google well either. But I don't know if you have any learnings from it. No, I'm the first result on Google. People writing about learning in public...
You're not first result anymore, I guess. Type learning public in Google. Well, yeah, yeah, yeah. But this is also like this in Google, it doesn't work either. That's what I'm saying. It's like how when you have like a movement. There's confusion about the like what you mean, like your intention is a little. Yeah, it's like I'm using I'm using a term that like I didn't invent. Yeah, but I'm kind of taking over. Yeah, but like they're just so much about that term already that it's hard to overcome.
If that makes sense, because public schools is like, well, it's, it's hard to overcome public schools, you know? So there's the right solution to this, which is to specify more clearly what you mean. And I'm not expecting you to do that, but so the right interface to search is actually an LLM. Like you should be talking to an LLM about what you want and the LLM translates its knowledge of you or knowledge of what people usually mean into a query that Excytin uses.
Which you have called auto-prompt, right? Yeah, but it's like a very light version of that. And really, it's just basically the right answer is it's the wrong interface. And very soon, the interface to search and really to everything will be LLMs. And the LLM just has a full knowledge of you, right? So we're kind of building for that world. We're skiing to where the puck is going to be. And so since we're moving to a world where LLMs are interfaced to everything, you should build...
a search engine that can handle complex LLM queries, queries that come from LLMs. Because you're probably too lazy, and I'm too lazy too, to write a whole paragraph explaining, okay, this is what I mean by this word. But an LLM is not lazy. And so the LLM will spit out a paragraph or more explaining exactly what it wants. You need a search engine that can handle that. Traditional search engines like Google or Bing, they're actually designed for humans typing keywords. If you give a paragraph to Google or Bing, they just completely fail.
And so Exa can handle paragraphs and we want to be able to handle it more and more until it's like perfect. What about opinions? Do you have lists? When you think about the list product, do you think about just finding entries? Do you think about ranking entries? I'll give you a dumb example. So on Lindy, I've been building the spot that every week gives me like the top fantasy football waiver pickups. But every website is like different opinions. I'm like, you should pick up these five players, these five players. When you're making lists,
Do you want to be kind of like also ranking and like telling people what's best or like are you mostly focused on just surfacing information? There's a really good distinction between filtering to like things that match your query and then ranking based on like what is...
your preferences. And ranking is, like, filtering is objective. It's like, does this document match what you asked for? Whereas ranking is more subjective. It's like, what is the best? Well, it depends what you mean by best, right? So first table stakes is let's get the filtering into a perfect place where you actually, like, every document matches what you asked for. No surgeon can do that today. And then ranking, you know, there are all sorts of interesting ways to do that where, like, you've maybe, you know, have the user, like,
specify more clearly what they mean by best. You could do, if the user doesn't specify it, you do your best, you do your best based on, uh, what people typically mean by best. But ideally like the user can specify, Oh, when I mean best, I actually mean ranked by the, you know, the number of people who visited that site, let's say is one example ranking or, Oh, what I mean by best, let's say you're listing companies. What I mean by best is like the ones that have, uh,
have the most employees or something like that. There are all sorts of ways to rank a list of results that are not captured by something as subjective as best. Yeah. I mean, it's like, who are the best NBA players in the history? It's like, everybody has their own. Right, right. But I mean, the search engine should definitely, even if you don't specify it, it should do...
as good of a job as possible yeah yeah no no totally yeah yeah it's a new topic to people because we're not used to a search engine that can handle like a very complex ranking system like you think to type in best basketball players and not something more specific because you know that's the only thing google could handle but if google could handle like oh basketball players ranked by like number of shots scored on average per game then you would do that but you know they can't do that so
Yeah, that's fascinating. So you haven't used the word agents, but you're kind of building a search agent. Do you believe that that is agentic in feature? Do you think that term is distracting? I think it's a good term. I do think everything will eventually become agentic. And so then the term will lose power. But yes, what we're building is agentic in the sense that it takes actions. It decides when to go deeper into something. It has a loop, right? It feels different from traditional search, which is like...
an algorithm, not an agent. Ours is a combination of an algorithm and an agent. I think my reflection from seeing this in the coding space, where there's basically sort of classic framework for thinking about this stuff is the self-driving levels of autonomy, right? Level one to five. Typically the level five ones all failed.
Because there's full autonomy and we're not there yet. And people like control. People like to be in the loop. So the level ones was co-pilot first and now it's like cursor and whatever. So I feel like if it's too agentic, it's too magical, like a one shot, I stick a paragraph into the text box and then it spits it back to me. It might feel like I'm too disconnected from the process and I don't trust it. As opposed to something where I'm more intimately involved with the research product.
I see. So like, wait, so the earlier versions are... So if, trying to stick to the example of the basketball thing, like best basketball player, but instead of best, you actually get to customize it with whatever the metric is that you guys care about. I'm still not a basketballer. Yeah.
But, you know, people like to be in... My thesis is that agents, level five agents failed because people like to kind of have drive assist rather than full self-driving. I mean, a lot of this has to do with how good agents are. Like at some point, if agents for coding...
are better than humans at all tasks than humans block. We're not there yet. So in a world where we're not there yet... What you're pitching us is you're kind of saying you're going all the way there. I think O1 is also very full self-driving. You don't get to see the plan. You don't get to affect the plan. You just fire off a query and then it goes away for a couple minutes and comes back, right? Which is effectively what you're saying you're going to do too. And you think there's a... There's an in-between. Okay, so in building this product, we're exploring...
new interfaces because what does it mean to kick off a search that takes 10 minutes? Is that a good interface? Because what if the search is actually wrong or it's not exactly specified to what you mean? Which is why you get previews. Yeah, you get previews. So it is iterative. But ultimately, once you've specified exactly what you mean, then you kind of do just want to kick off a batch job, right? So perhaps what you're getting at is like,
there's this barrier with agents where you have to like explain the full context of what you mean. And a lot of failure modes happen when you have, when you don't. Yeah. There's failure modes from the agent just not being smart enough. And then there's failure modes from the agent not understanding exactly what you mean. And there's a lot of context that is shared between humans that is like lost between like humans and, and this like,
new creature. Yeah, because people don't know what's going on. I mean, to me, the best example of system prompts is like, why are you writing you're a helpful assistant? Of course, you should be a helpful assistant. But people don't yet know, can I assume that you know that? And now people write, oh, you're a very smart software engineer. You never make mistakes. Were you going to try and make mistakes before? So I think people don't yet have
and understanding. Like with driving, people know what good driving is. It's like, don't crash, stay within kind of like a certain speed range. It's like, follow the directions. It's like, I don't really have to explain all of those things, I hope. But with AI and like models and like search, people are like, okay, what do you actually know?
What are like your assumptions about how search, how you're going to do search and like, can I trust it? You know, can I influence it? So I think that's kind of the, the middle ground, like before you go ahead and like do all the search, it's like, can I see how you're doing it? And that may be helpful. Your work. Kind of like, yeah. Yeah. Yeah. No, I mean, yeah. So you're saying even if you've crafted a great system prompt, you want to be part of the process itself because yeah,
the system prompt doesn't, it doesn't capture everything, right? So, yeah. A system prompt is like you get to choose the person you work with. It's like, oh, like I want, I want a software engineer who thinks this way about code. But then even once you've chosen that person, you can't just give them a high level command and they go do it perfectly. You have to be part of that process. So, yeah, I agree. Yeah.
just a side note for my system, my favorite system prompt programming anecdote now is the Apple intelligence system prompt that someone, someone's a prompt injected it and seen it. And like the Apple intelligence has the words, like, please don't, don't hallucinate. And it's like, of course we don't want you to hallucinate. Right. Like, so it's exactly that, that what you're talking about, like we should train this in,
behavior into the model but somehow we still feel the need to inject it into the prompt and I still don't even think that we're very scientific about it like it I think it's almost like cargo culting like we have this like magical like turn around three times throw salt over your shoulder before you do something and like it worked the last time so let's just do it the same time now
There's no science to this. - I do think a lot of these problems might be ironed out in future versions, right? And they might hide the details from you. So it's like they actually, all of them have a system prompt that's like, you are a helpful assistant. You don't actually have to include it, even though it might actually be the way they've implemented it in the backend.
It should be done in RLAF. Okay, one question I was just kind of curious about. So this episode is, I'm going to try to frame this in terms of just the general AI search wars. You know, you're one player in that there's perplexity, chat, GPT search, and Google. But there's also like the B2B side.
We had Drew Houston from Dropbox on, and he's competing with Glean, who we've also had Didi from Glean on. Is there appetite for EXA for my company's documents? There is appetite, but I think we have to be disciplined, focused, disciplined. I mean, we're already taking on like
perfect web search, which is a lot. But, I mean, ultimately we want to build a perfect search engine, which definitely for a lot of queries involves your personal information, your company's information. And so, yeah, I mean, the grandest vision of EXA is perfect search really over everything. Every domain. You know, we're going to have an EXA satellite because satellites can gather information that is not available publicly. Gotcha. Can we talk about AGI? Yeah.
We never talk about AGI, but you had this whole tweet about O1 being the biggest kind of like AI step function towards it. Why does it feel so important to you? I know there's kind of like always criticism and saying, hey, it's not that smart, it's not that it's better. It's like blah, blah, blah. What did you see? So you say this is what Ilyas see, what Sam see, what they will see. I've just, you know, been connecting the dots. I mean,
This was the key thing that a bunch of labs were working on, which is like, can you create a reward signal? Can you teach yourself based on a reward signal? Whether you're, if you're trying to learn coding or math, if you could,
have one model, say, be a grading system that says, like, you have successfully solved this programming assessment, and then one model, like, be the generative system that's like, here are a bunch of programming assessments. You could train on that. So basically, whenever you could create a reward signal for some task, you could just generate a bunch of tasks for yourself, see that, like, oh, on two of these thousand, you did well, and then you just train on that data. It's basically, I mean, creating your own data for yourself. And, like, you know, all the labs working on that, opening AI,
built the most impressive product doing that. And it's just very, it's very easy now to see how that could like scale to just solving, like solving programming or solving mathematics, which sounds crazy, but everything about our world right now is crazy. And so I think if you remove that whole, like, oh, that's impossible. And you just think really clearly about like what's now possible with like what they've done with O1, it's easy to see how that scales. How do you think about
older gpd models then should people still work on them you know if like obviously they just had the new haiku like is it even worth spending time like making these models better versus just you know sam talked about o2 at that day so obviously they're they're spending a lot of time in it but then you have maybe the gpu poor which are still working on making llama good
And then you have the follower labs that do not have an O1-like model yet. Yeah, this kind of gets into like, what will the ecosystem of models be like in the future? And is there room, is everything just going to be O1-like models? I think, I mean, there's definitely a question of like inference speed and if certain things, like O1 takes a long time because it has to think.
- Well, I mean, O1 is two things. It's like one, it's bootstrapping itself, it's teaching itself, and so the base model is smarter. But then it also has this inference time compute where it could spend many minutes or many hours thinking. So even the base model, which is also fast,
it doesn't have to take minutes it could take is better smarter i believe all models will be trained with this paradigm like you'll want to train on the best data but there will be many different size models from different very many different like companies i believe yeah because like i don't yeah i mean it's hard to predict but i don't think opening eye is going to dominate like every possible lm for every possible use case i think for a lot of things like
you just want the fastest model and that might not involve O1 methods at all. I would say if you were to take the EXA being O1 for search literally, you really need to prioritize search trajectories.
Like almost maybe paying a bunch of grad students to go research things and then you kind of track what they search and what the sequence of searching is. Because it seems like that is the gold mine here, like the chain of thought or the thinking trajectory. Yeah, when it comes to search, I've always been skeptical of human label data. Okay. Yeah, please. We tried something at our company at Exa recently where...
me and a bunch of engineers on the team labeled a bunch of queries. And it was really hard. You have all these niche queries, and you're looking at a bunch of results, and you're trying to identify which matches the query. It's talking about...
the intricacies of some biological experiment or something. I have no idea. I don't know what matches. And what labelers like me tend to do is just match by keyword. I'm like, oh, this document matches a bunch of keywords, so it must be good. But then you're actually completely missing the meaning of the document. Whereas an LLM like GPT-4 is really good at labeling. And so I actually think we get by, which we are right now doing, using LLMs as the labelers. Specifically for search, I think it's interesting. It's different between
Like, search and, like, GB5 are different because GB5 might benefit from training on a lot of PhD notes because, like, GB5 might have to do, like, very, very complex, like, problem solving when it's given an input. But with search, it's actually a very different problem. You're asking simple questions about...
billions of things. So like, whereas like GB5 is asking a really hard, it's like solving a really hard question, but it's one, it's like one question, a PhD level question. With search, you're asking like simple questions about billions of things. Like, is this a startup? Did this person write a blog post about search? You know, those are actually simple questions. You don't need like PhD level training data. Does that make sense? Yeah. What else we got here? NAPBODs. Oh yeah. Yeah.
So just generally, I think EXA has a very interesting company building vibe. You have a meme lord CTO, I guess. I don't know. And you just generally are counter consensus in a bunch of things. What is the culture at EXA? Yeah.
- Yeah, me and Jeff are, I mean, we've been best friends since like, we met like first day of college, and we've been best friends ever since. And we have a really good vibe, I think, that's like intense but also really fun and like funny, honestly. We have a ton of, we just laugh a lot, a ton at EXA. And I think that's just like, you see that in every part of our culture. We don't really care about how the world sees anything. Me and Jeff are just like that. We're just thinking, really just like,
what should we do here? Like, what do we need? And so in the nap pod case, it was like, people get tired a lot when they're coding or doing anything really. And like, why can't we just sleep here or like nap? And okay, if we need a nap, then we should get nap pods. It's crazy to me that there aren't nap pods in lots of companies because like I get tired all the time. I take a nap like every other day, probably for like 20 minutes. I'm actually never actually napping. I'm just thinking about a problem, but closing my eyes really like
Like, first of all, it makes me come up with more creative solutions and then also actually gives me some rest. So it's just awesome. Google was the original company that had the nap pods at work, right? Oh, okay. Well, at one point, Google was thinking for first principles of everything too. And that was reflected in their nap pods. But also, you like didn't just get a nap pod for your office. You like found something from China and you're like, who wants to get in on this? Let's get a container full of them. Yeah, well, we try to be frugal. So like we were looking at like different nap pods and then...
At some point, we were like, wait, China probably has solved this problem. And so then we ordered it from China. And it was actually so heavy. When it came off the truck, it was like 500 pounds. And the truck was having trouble putting it on the ground. And so me and the delivery guy were trying to hold it. And then we couldn't. We were struggling. So someone came out on the street and started helping us. You didn't hurt yourself. No, it was really dangerous. But we did it. And it was awesome. It's funny. I was reading the TechCrunch article about it.
There was a TechCrunch article on the nap pods? Yeah. And then Jeff explained, well, they quote Jeff. And this paragraph says, so the nap pods maintain employees' ability to stop work and sleep rather than the idea that, in quotes, employees are slaves. Close quote. Ha ha ha.
I don't know. Jeff was away with words. I'm like, I'm sure there's not one event, you know, but I'm curious, like, just like how people, there's always like this, I think for a little bit, it went away about like startups and kind of like hustle culture and all that. And I think now with AI, people are like, have all these feelings towards AI that are kind of like. I think it's a pro hustle culture, right? Yeah. But I mean, I mean, ideally the hustle is people are just having fun, which is people, people are just having fun. Yeah. But I would say from the outside, it's like people don't like it.
I'm saying people not in AI and kind of like in tech, they're kind of like, oh, these guys are at it again. These are like the same people that gave us underpaid drivers or like whatever. It's like, so it was just funny to see
Somehow they wanted to make it sound like Jeff was saying employees are slaves. Oh, yeah. I don't know. That doesn't make sense. But yeah, I mean, OK, I can't imagine a more exciting experience than like building something from scratch. That's like a huge deal with a bunch of your friends. Our team is going to look back in 10 years and think this was like the most beautiful experience that you could have.
in life and like that's how I think about it and yeah that's just so it's not a hustle or not it's like is this like does this satisfy your core desire to like build things in the world and it does yeah
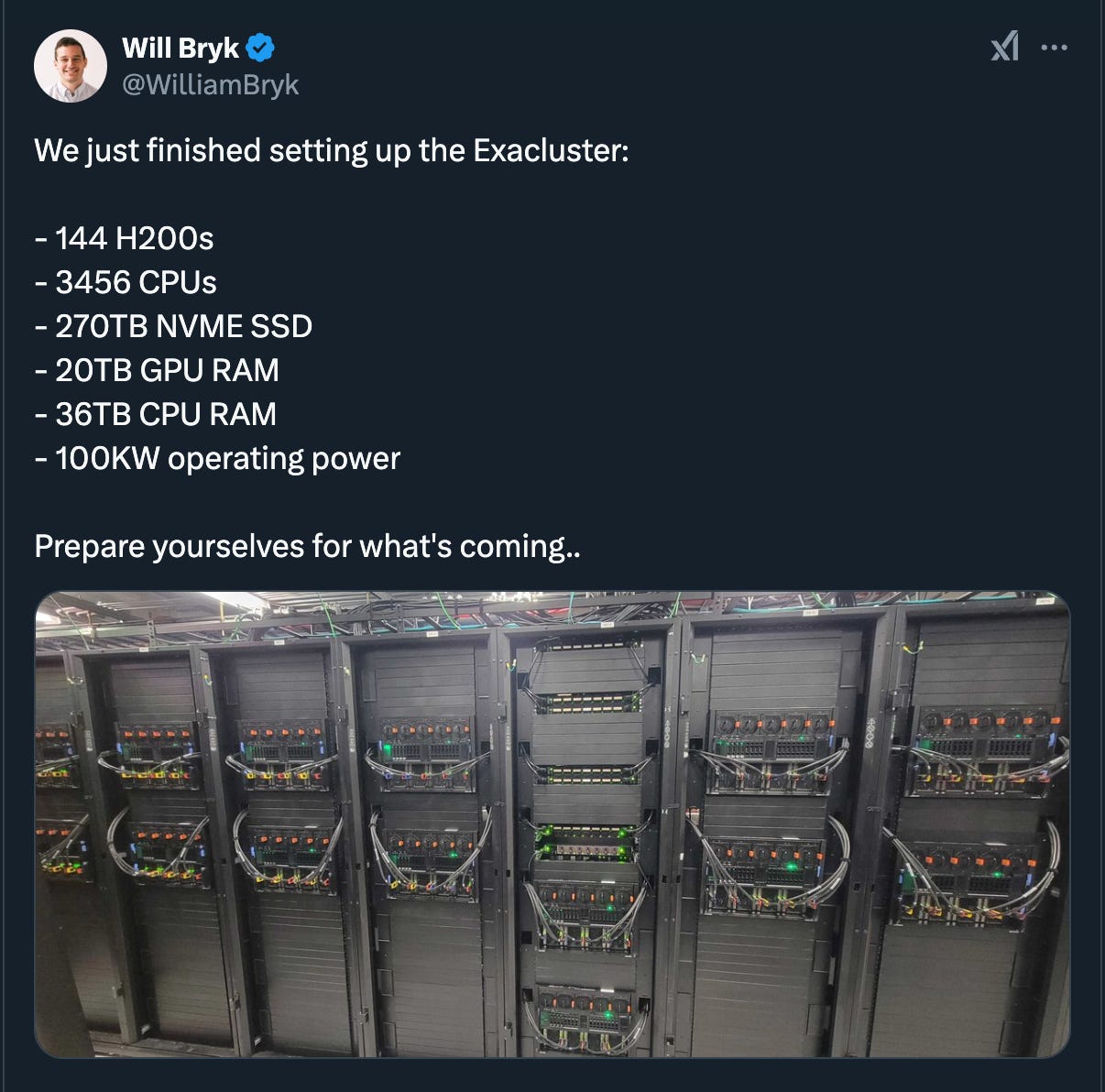
Anything else we didn't cover? Any parting thoughts? Are you hiring? Are you, obviously you're looking for more people to use it, but. Yeah, yeah. We're definitely hiring. We're growing quite fast and we have a really smart team of engineers and researchers. And we now have, we just purchased a $5 million H200 cluster. So we have a lot more compute to play with. Do you run all your own inference? We do a mix of our cluster and like AWS. Inference, we use these, so we have our current cluster, which is like
A100, and now we've updated to a new one. We use it for training and research. What's the training versus inference budget?
Like, is it like, is it 50-50? Is it? Yeah, there will be more inference for search for sure. The other thing I mentioned, so by the way, I'm like sidetracking, but I'm just kind of throwing this in there because I always think about the economics of AI search. Like for those, I think if you look up, there's the upper limit is going to be whatever you can monetize off of ads, right? So for Google, let's say it's like a one cent per thousand views, something like that. I don't know the exact number, the exact numbers floating around out there. That means that's your revenue, right? Then your cost has to be lower than that. And
And so at some point, like for an LLM inference call to be made for every page view, you need to get it lower than the money that you take in for that. And like one of the things that I was very surprised for perplexity and character as well was that they couldn't get it so low that it would be reasonable. I think for you guys...
It is a mix of front-loading it by indexing. So you only run that compute like once a month, once a quarter, whatever you do re-indexing. And then it's just a little bit more when you do inference, when this search actually gets done, right? So I think when people work out the economics of such a business, they have to kind of think about where do you put the costs, right?
Yes, yes. I mean, definitely you have to, you cannot run LLMs over the whole index, you know, billions of things at query time. So you have to pre-process things usually with LLMs. But then you can do a re-rank over like, you know, 10, 30, 100, depending on a thousand, depending on how, you know, you could play with different sizes of transformers to get the cost to work out.
I mean, one really interesting thing is like we're building a search engine at a time where LLM costs are going down like crazy. When some very useful tool goes down in cost by 200x in like the space of a couple of years, there are going to be new opportunities in search, right? So like to not integrate this and build off, to not like rethink search from scratch, the search algorithm itself, given the fact that things are going down 200x is crazy. Thank you so much for coming on, man. Yeah, thank you. This was so fun. Really fun.
Thank you.