Shownotes Transcript
Audio note: this article contains 81 uses of latex notation, so the narration may be difficult to follow. There's a link to the original text in the episode description.
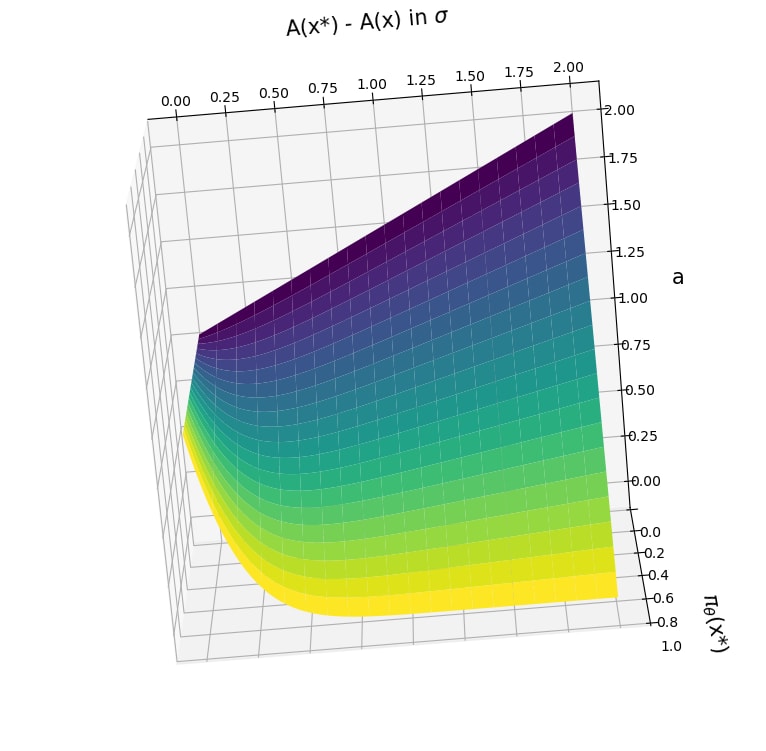
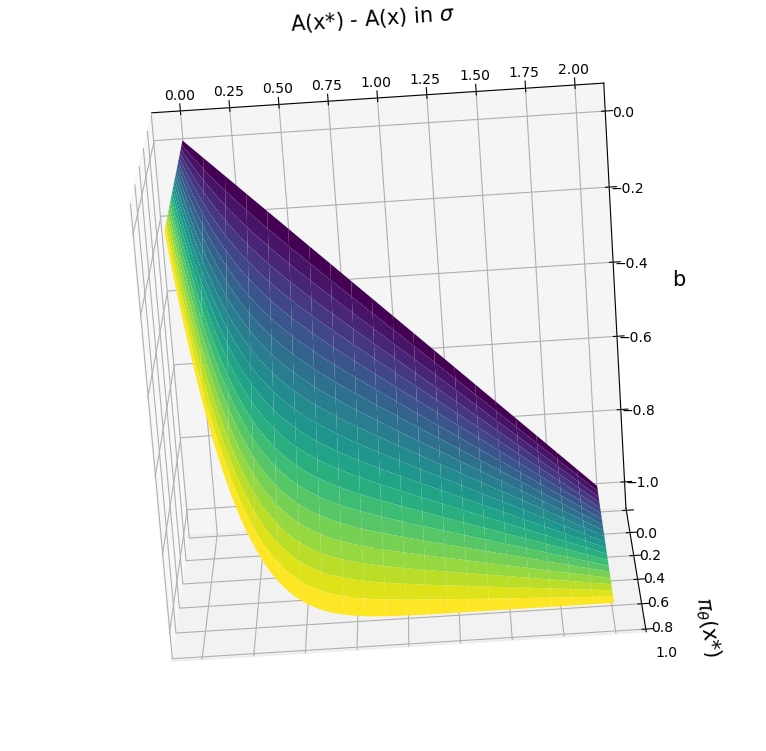
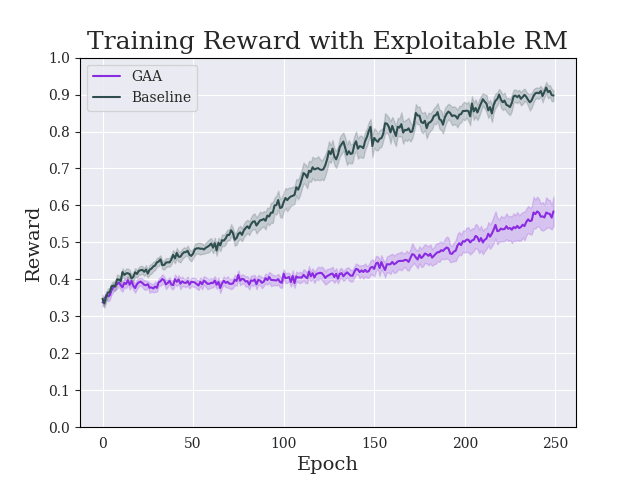
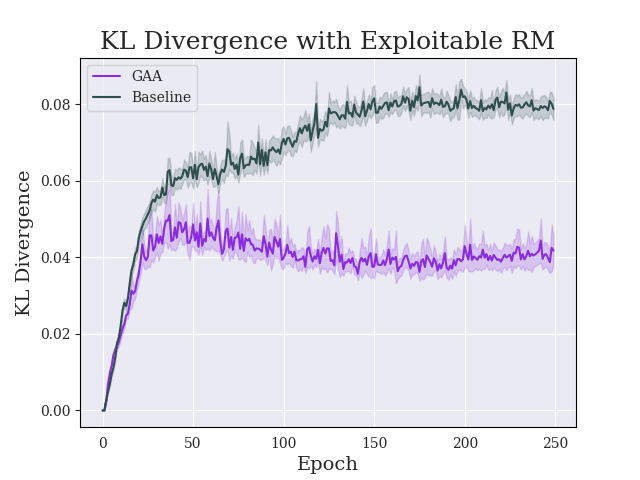
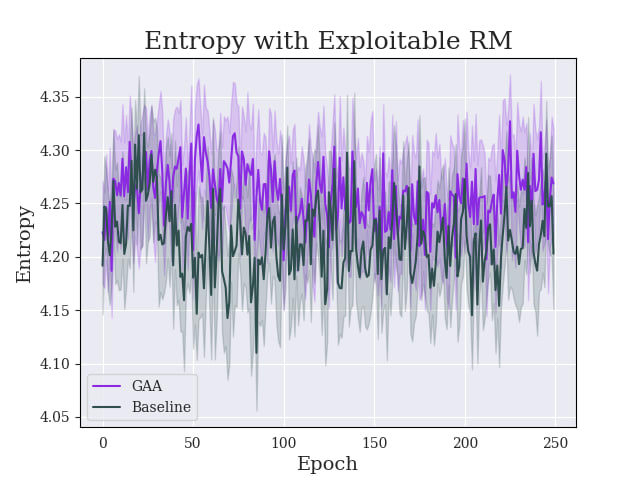
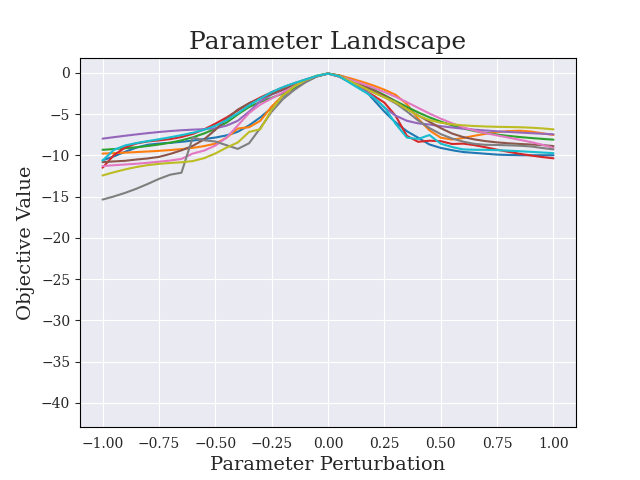
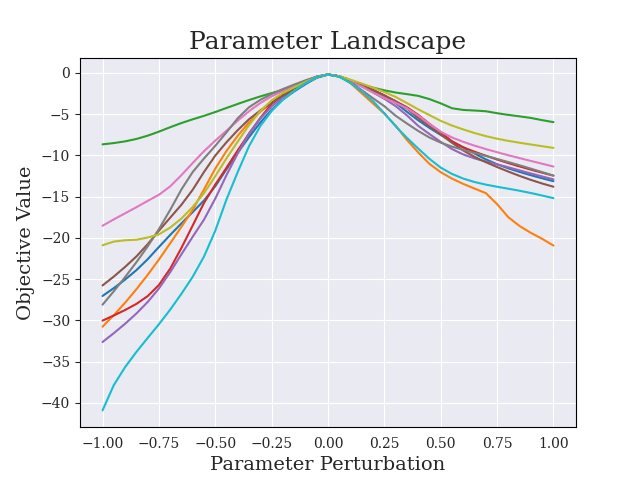
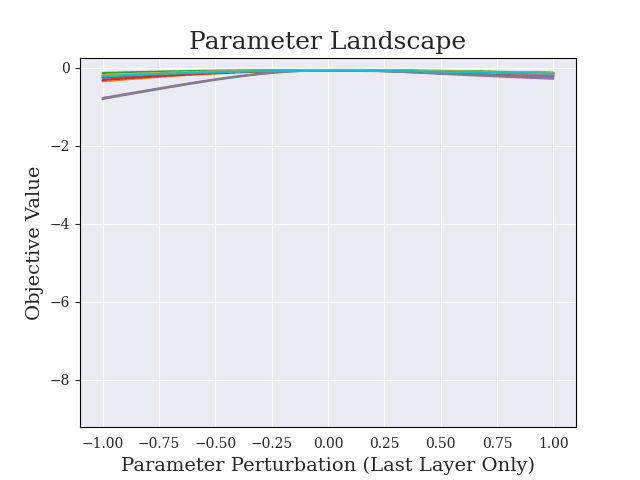
Greedy-Advantage-Aware RLHF addresses the negative side effects from misspecified reward functions problem in language modeling domains. In a simple setting, the algorithm improves on traditional RLHF methods by producing agents that have a reduced tendency to exploit misspecified reward functions. I also detect the presence of sharp parameter topology in reward hacking agents, which suggests future research directions. The repository for the project can be found here.
** Motivation** In the famous short story The Monkey's Paw by W.W. Jacobs, the White family receives a well-traveled friend of theirs, Sergeant-Major Morris, and he brings with him a talisman from his visits to India: a mummified monkey's paw. Sergeant Major Morris reveals that the paw has a magical ability to [...]
Outline:
(00:46) Motivation
(06:40) A Simplified Look at PPO in RLHF
(08:40) Greedy-Advantage-Aware RLHF
(12:37) Evaluation
(12:41) Main Results
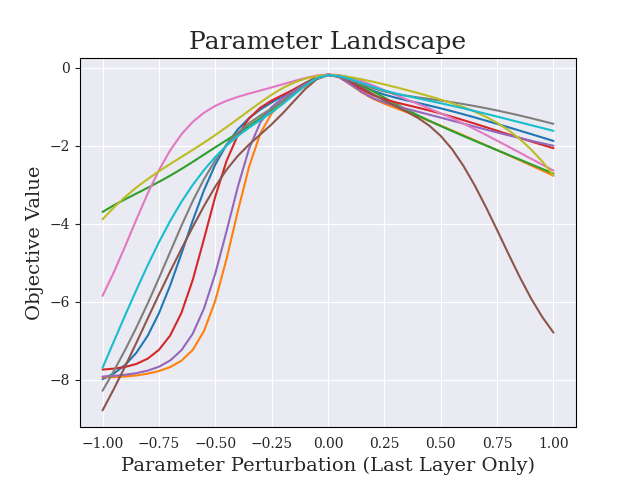
(17:11) Sharpness
(22:15) Efficiency
(23:03) Discussion
(24:25) Limitations and Future Work
(25:56) Acknowledgements
(26:20) Appendix
The original text contained 7 footnotes which were omitted from this narration.
The original text contained 4 images which were described by AI.
First published: December 27th, 2024
Source: https://www.lesswrong.com/posts/s6wew6qerE4XHmbTL/greedy-advantage-aware-rlhf)
---
Narrated by TYPE III AUDIO).
Images from the article: