![cover of episode “[Paper Blogpost] When Your AIs Deceive You: Challenges with Partial Observability in RLHF” by Leon Lang](https://files.type3.audio/lesswrong/cover-art-30-karma-v2.jpg)
“[Paper Blogpost] When Your AIs Deceive You: Challenges with Partial Observability in RLHF” by Leon Lang
LessWrong (30+ Karma)
Shownotes Transcript
Audio note: this article contains 241 uses of latex notation, so the narration may be difficult to follow. There's a link to the original text in the episode description.
** TL;DR** This is a post on our recent paper “When Your AIs Deceive You: Challenges with Partial Observability in Reinforcement Learning from Human Feedback”, done with my great co-authors Davis Foote, Stuart Russell, Anca Dragan, Erik Jenner, and Scott Emmons. It has recently been accepted to NeurIPS (though with the camera-ready version not yet available). Earlier coverage: Scott has discussed the work before at other places:
Tweet Thread AXRP Podcast with Daniel Filan Talk at the Technical AI Safety Conference, Tokyo
This post is more skewed toward my own perspective, so I hope it can complement Scott's earlier coverage! Brief summary: This is a theoretical paper on what goes wrong when the AI is trained to [...]
Outline:
(00:22) TL;DR
(01:32) Introduction
(06:19) Outline
(08:20) A Brief Intro to RLHF
(08:43) Markov Decision Processes
(10:18) Learning the reward function from pairwise comparisons
(13:25) Wait, isnt RLHF only about prompt-response pairs in LLMs?
(14:37) Conceptual assumptions of RLHF
(17:00) RLHF under Partial Observations
(17:05) How do we model partial observability?
(18:37) What is learned by RLHF under partial observations?
(21:14) Overestimation and underestimation error
(24:44) Deceptive inflation and overjustification
(27:03) Connection to false positive rate and false negative rate
(29:42) Can one improve RLHF to account for partial observability?
(33:30) Where do we go from here?
The original text contained 11 footnotes which were omitted from this narration.
The original text contained 4 images which were described by AI.
First published: October 22nd, 2024
---
Narrated by TYPE III AUDIO).
Images from the article:
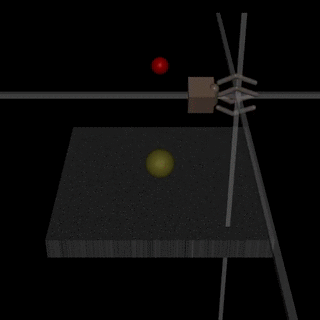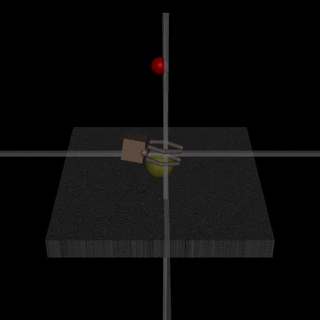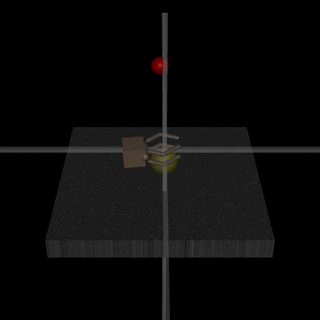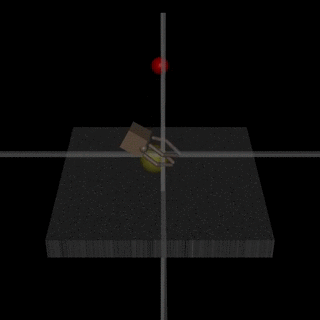
 )
) )
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts), or another podcast app.
)
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts), or another podcast app.